2022年8月23日(火)から25日(木)の3日間にわたり開催となった、“CEDEC 2022”(Computer Entertainment Developers Conference 2022)。こちらの記事では、その3日目に行なわれたセッション“機械学習によるリップシンクアニメーション自動生成技術とFINAL FANTASY VII REMAKEのアセットを訓練データとした実装実例”の内容をお届けしていく。
本セッションの講演者は、株式会社スクウェア・エニックスの中田聖人氏(テクノロジー推進部R&Dエンジニア)、グラシア ヒル レアンドロ氏(AI部シニアAIエキスパート)、原龍氏(第一開発事業本部 ディビジョン1 リードアニメーションプログラマー)、岩澤晃氏(第一開発事業本部 ディビジョン1 フェイシャルディレクター)の4名だ。



なお、レアンドロ氏の担当パートは英語音声に日本語字幕の表示という形で進行した。また、講演で紹介する技術はまだ開発中のものであり、まだ将来的な開発タイトルへの本実装が決まっているわけではない点にもご留意いただきたい。

ハイクオリティーかつ準備負担も少ない次世代リップシンク
当講演では冒頭にふたつの動画が再生された。同じセリフを『ファイナルファンタジーVII リメイク』(以下、『FF7 リメイク』)の主人公キャラクター・クラウドがしゃべっている動画だ。


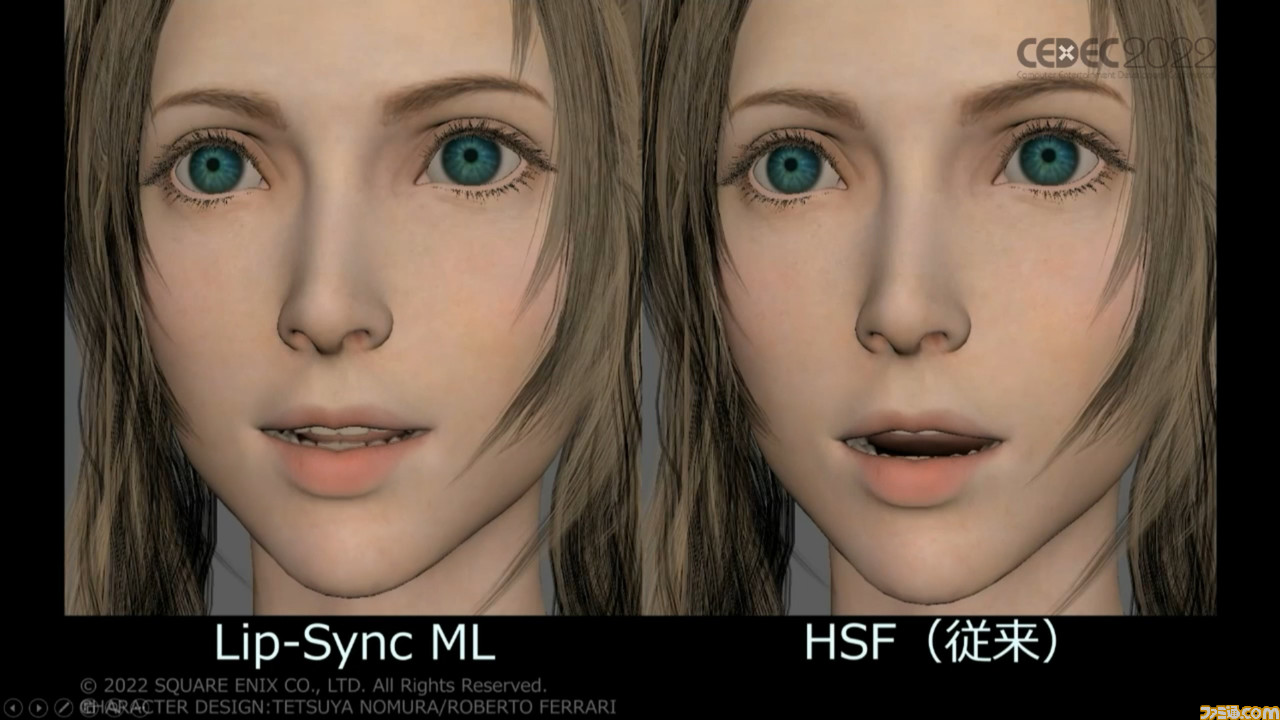
並べて比較すると、左の動画のほうはやや口の動きが大げさに見えたり、セリフと合っていない口パクが見られたりなどの点が目立った。それに対して右の動画では、静かな表情と感情にしっくりとくる、セリフとかみ合った口の動きが見られた。
今回の講演で扱う“リップシンクアニメーション”を活用すると、ここまで違いが出るということか。ただ、リップシンクアニメーションの作成には絶対的な課題もある。

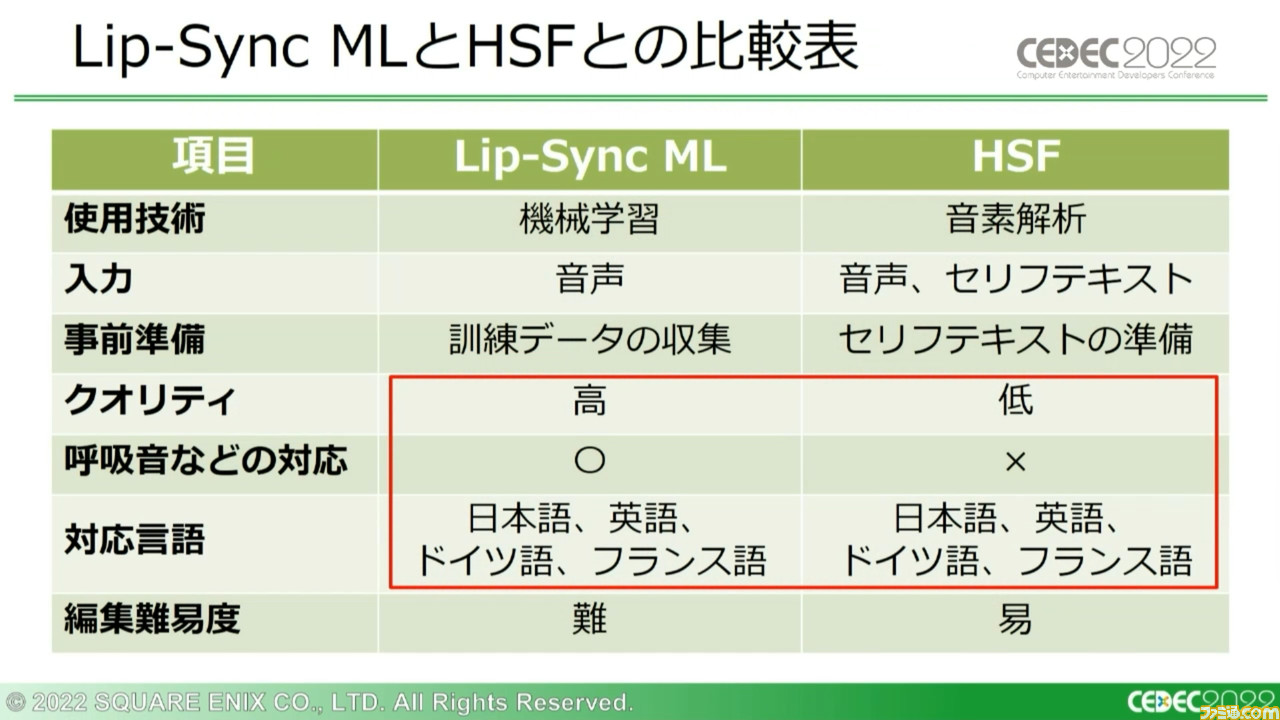
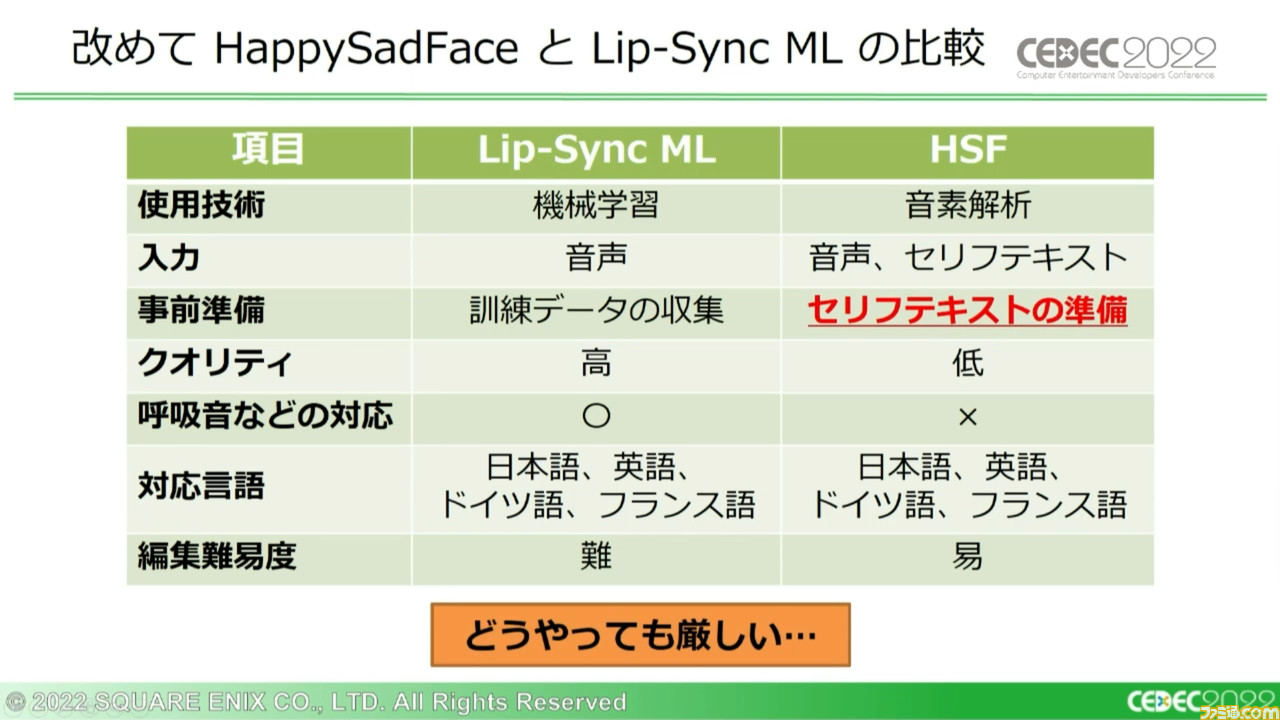
そのため、多くの企業が現在もリップシンクアニメーションの自動生成技術開発に取り組んでいる。スクウェア・エニックスでは従来、“音素”をベースにした“HappySadFace”(以下、HSF)というリップシンクアニメーション作成プログラムを使用していた。しかしこのシステムにも問題がいくつかあり、それを解消すべく新たに“Lip-Sync ML”という、“機械学習”をベースとしたシステムを開発したという。

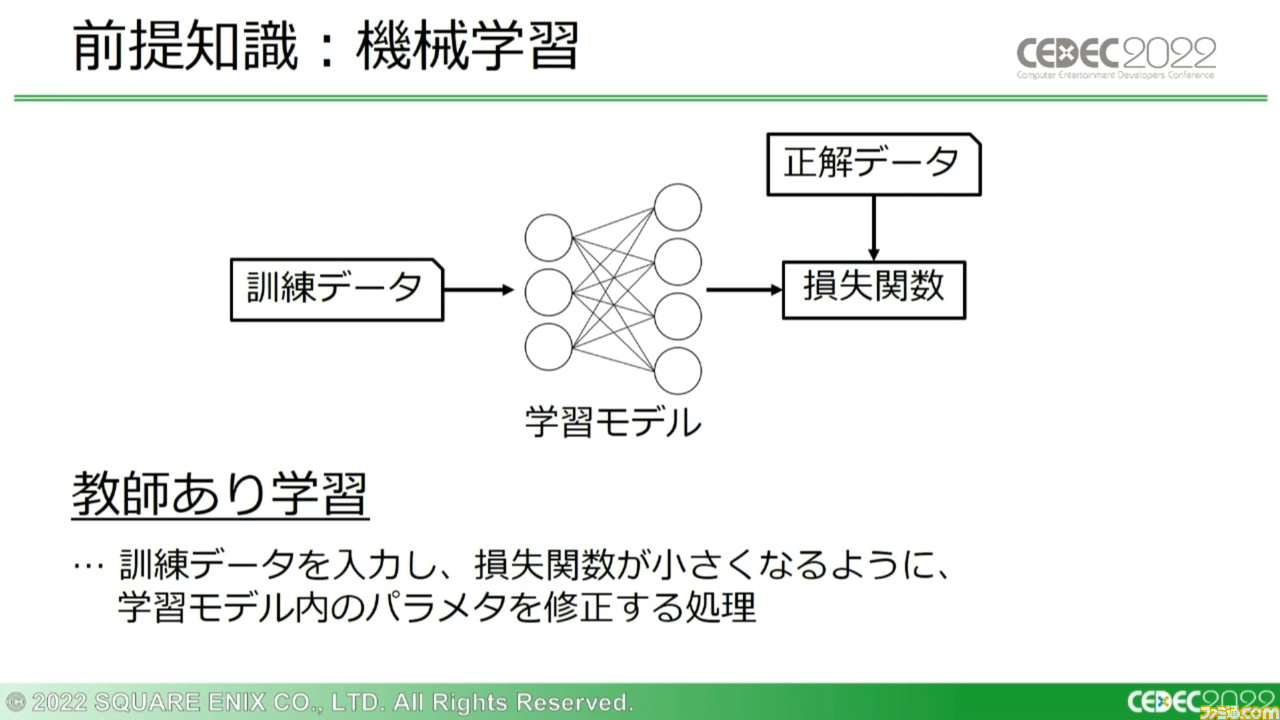
まずはこの技術を理解するための、前提知識が解説された。“機械学習”とは、大量の“訓練データ”を与えることで、新しいデータを与えられた際にもっとも期待に近いデータを出力できるように学習していくシステムを指す。
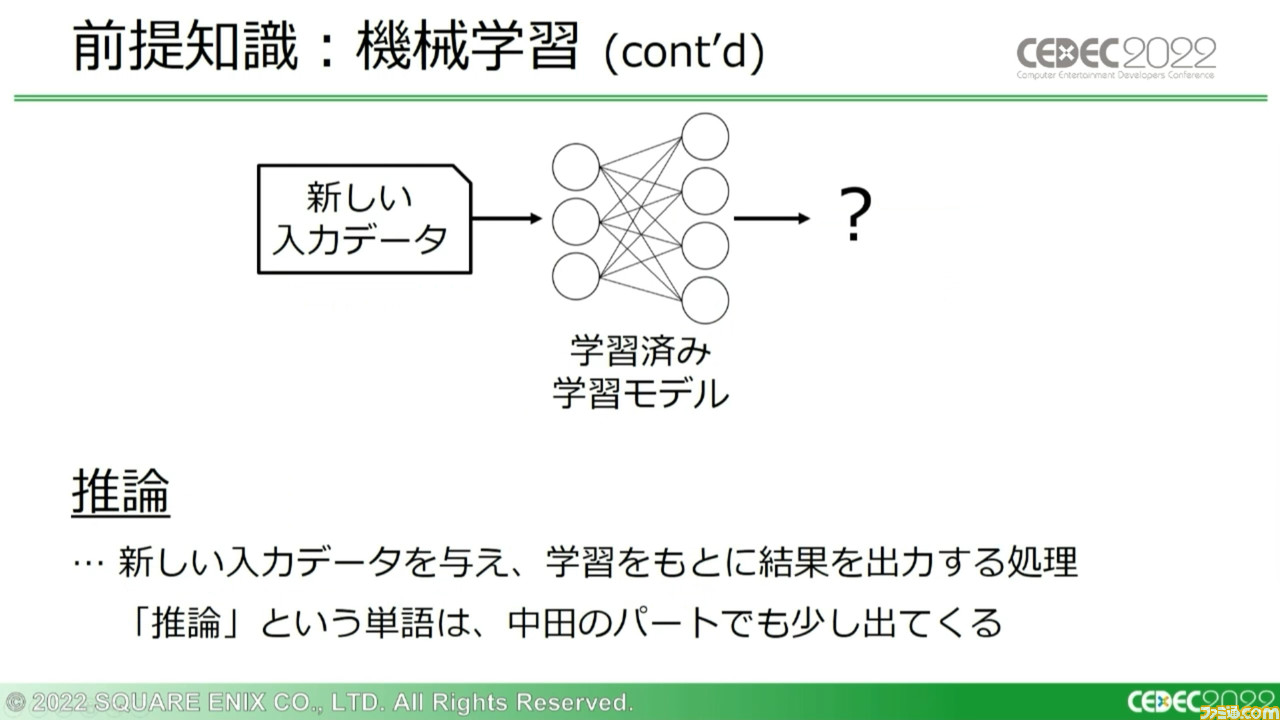
機械学習を構成する代表的な処理としては、“教師あり学習”と“推論”が挙げられる。教師あり学習は訓練データの入力時、学習データと正解データの差異(損失関数)が小さくなるように、学習モデル内のパラメーターを修正していく処理のこと。推論はその処理をもとに学習されたモデルに、別の入力データを与えることで新たな出力を得る処理のことだ。
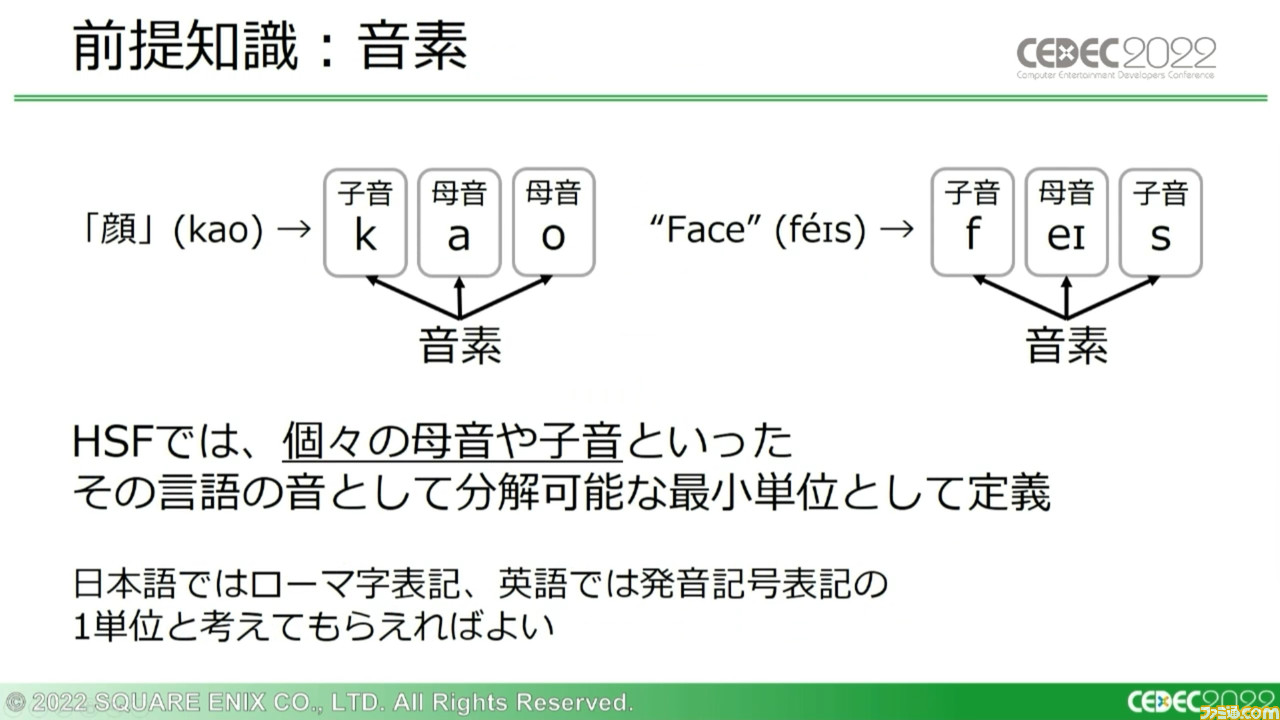
HSFが用いる“音素”についてはさまざな定義や議論がされているが、HSFでは個々の母音や子音といった音として分解可能な最小単位と定義している。
その音素に関わる“音素解析”というフローがある。音声データを解析し、どの部分がどの音素に対応するかを把握するためのものだ。

引き続きその前提知識を踏まえて、従来から使用されているHSFの概要が解説された。HSFは音声データ、ならびにセリフのテキストデータから音素解析を行ない、リップシンクアニメーションを生成するシステムだ。
途中の過程はここではいったん置いておいて、実際に何をしているのかというと、解析された各音素に“口の形”を割り当てているのだ。ただ、ひとつひとつの音素に口の形を登録するのは数的に非効率なので、“Lipmap”というデータにいくつかの口の形状を記録させている。

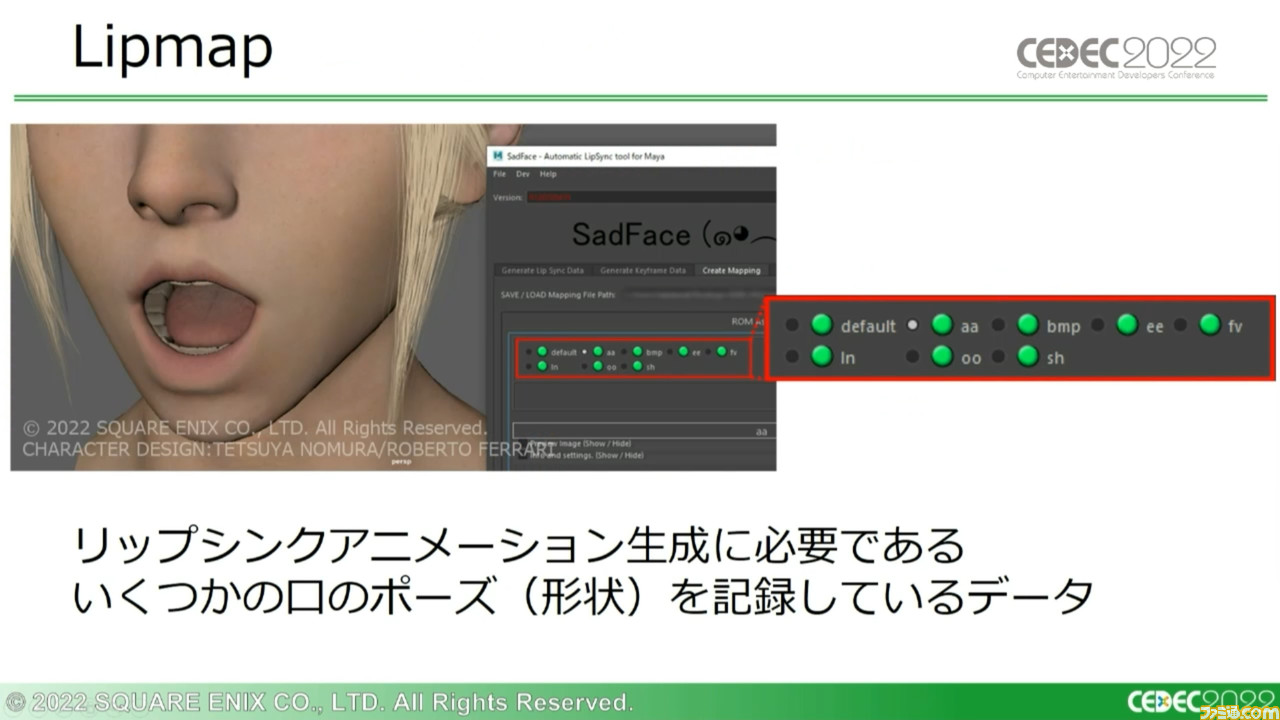
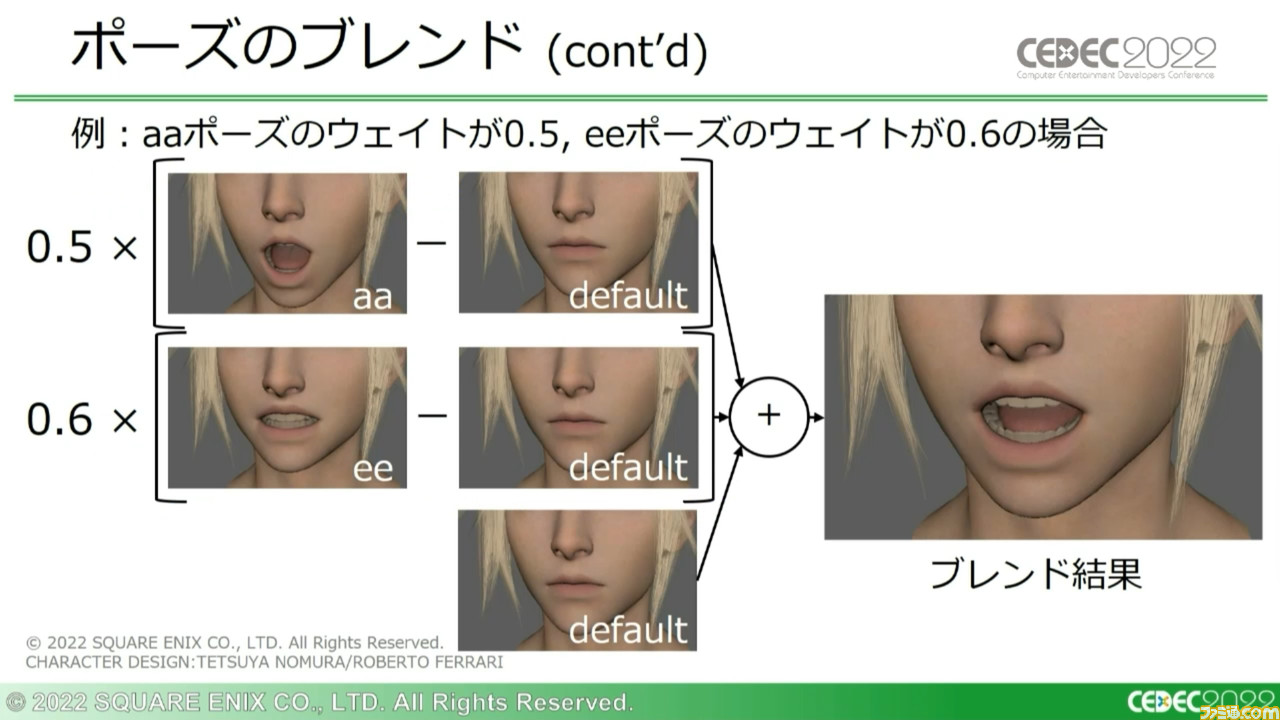
『FF7 リメイク』の場合を例に挙げると、基準となる口を動かさないポーズ“default”をはじめ、口を大きく開いた“aa”、口を横に広げた“ee”などの複数のポーズを登録。どの程度それらのポーズを反映させるかを指定する数値“ポーズウェイト”をもとに、defaultとの差分をブレンドして使用した。




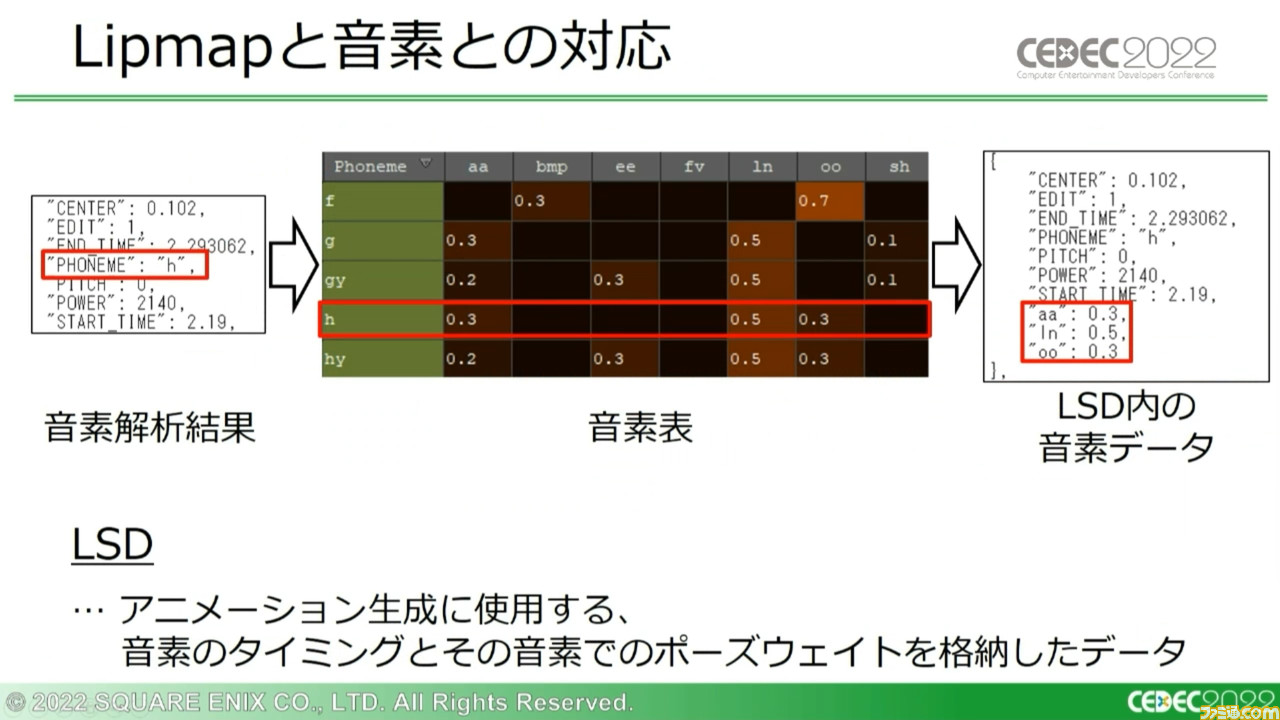
また、HSF内には音素に対応してどのようなポーズウェイトをブレンドするかを記録した“音素表”が組み込まれており、音素解析結果からアニメーション生成用のポーズウェイトなどを格納したデータ“LSD”を生成。『FF7 リメイク』では同一キャラクターに対して、感情に応じて複数のLipmapを準備し切り替えて使用していたという。
このように便利なHSFだったが、セリフテキストと音声が不一致となる場合、つまり呼吸音やアドリブボイスが入った場合に精度が大きく落ちる点が解決すべき課題とされていた。
講演ではここで『FF7 リメイク』のヒロイン・エアリスのリップシンクアニメーション動画を再生したが、明らかにセリフがない部分で、大きく口が動いていた。言葉を発する直前の呼吸音に音素として反応し、アニメーションが生成されてしまったのだ。

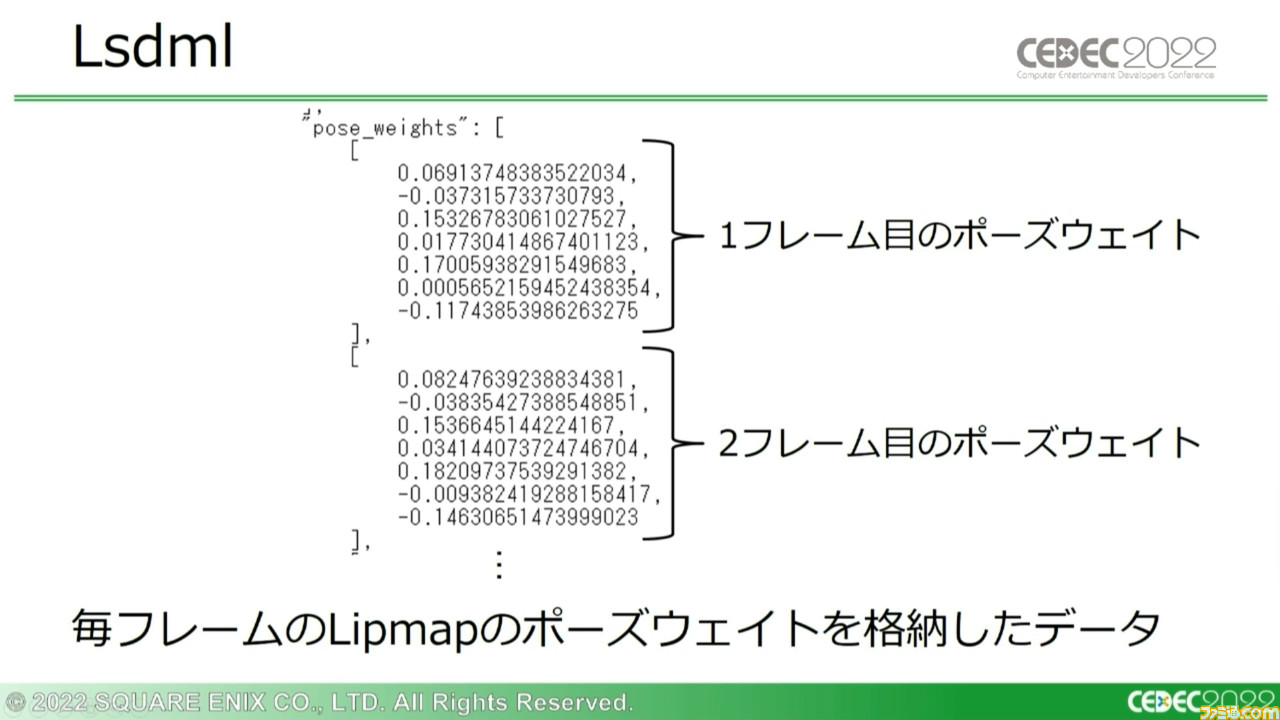
この問題を解決するため、音声のみの入力から直接アニメーションを自動生成するべく開発された機械学習ベースのシステムが、今回の講演で紹介する“Lip-Sync ML”だ。アニメーションデータと同時にHSFと同じワークフローを取れるように、Lipmapのポーズウェイトを“Lsdmlデータ”として出力する仕組みも搭載されている。
使用方法も非常に単純明快。音声データを読み込んで“Generate”ボタンを押すと機械学習システムの推論が走り、数十秒ほどでアニメーションが生成。アニメーションはそのまま3Dゲーム開発ツール“Maya”に出力され、その場で再生できる。
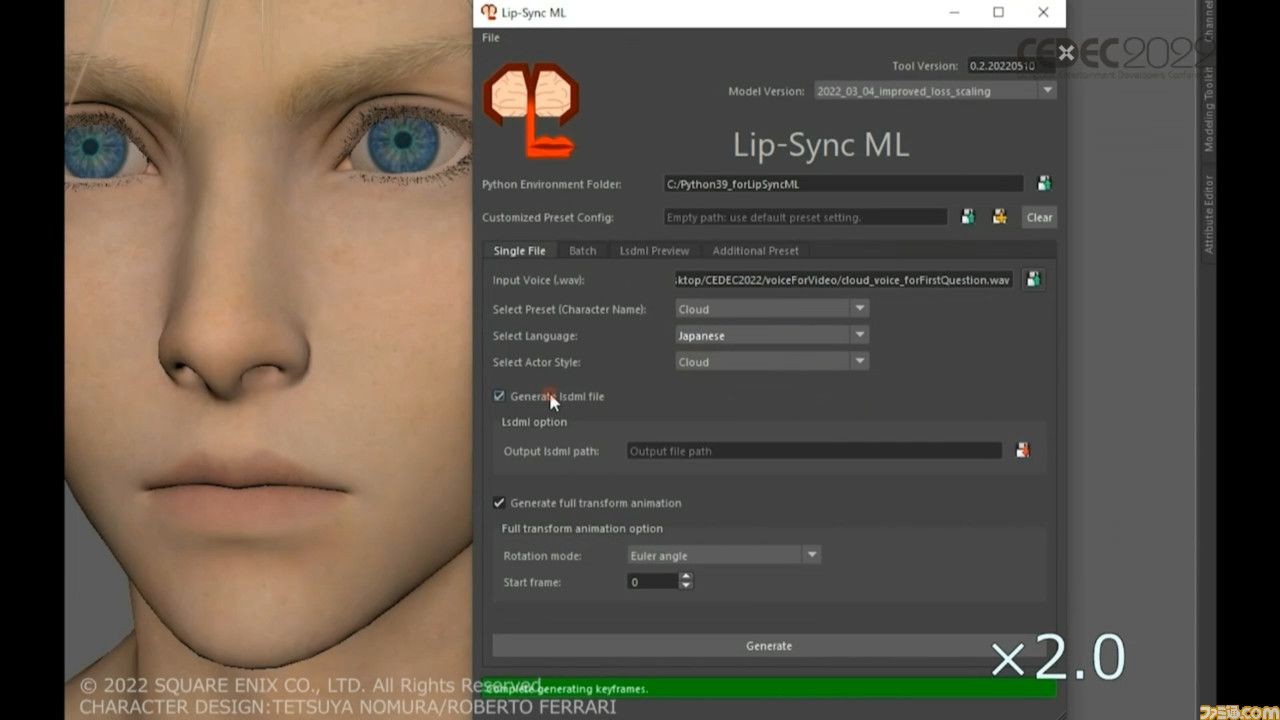

続いてほかのセリフやキャラクターに同じ処理を適用した際の動画も再生され、いずれからも呼吸音などには過剰に反応せず、自然な形で口が動いている様子が見て取れる。息継ぎに関してはHSFとの比較動画が再生され、とても自然な動きになっているのがわかった。
提示されたHSFとの比較表によると、HSFと同様に4か国語に対応可能とのこと。少なくともここまでの紹介範囲に絞るなら完全に上位互換と言えるだろう。
さらに、人型以外のモデルに対してもリップシンクアニメーション生成が可能となっている。講演内では『FF7 リメイク』の人語を話せる四足歩行獣のキャラクター・レッドXIIIに適用した際の動画も再生された。

Lip-Sync MLはシステム構成にも利便性が光る
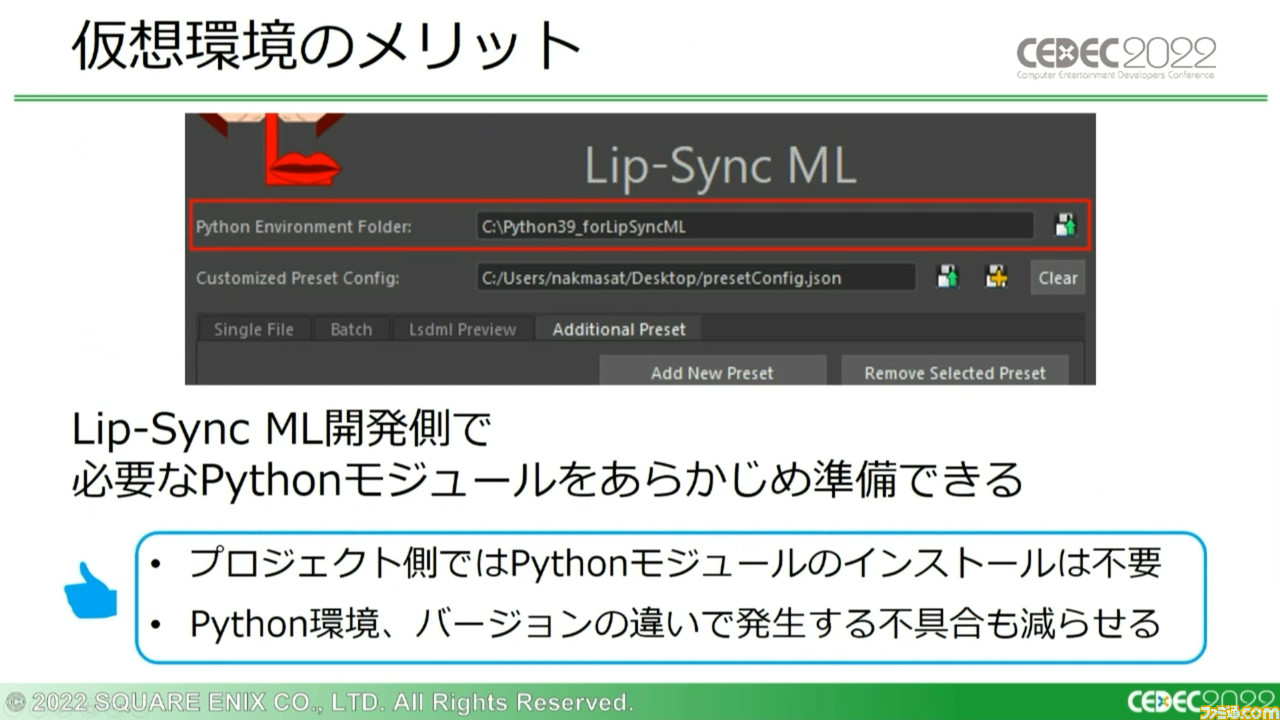
講演では続いて、Lip-Sync MLのシステム構成が解説された。システムを構成するにあたりMayaと機械学習とを連携させる必要があったが、両者に用いられていたプログラミング言語“Python”のバージョンが異なっていたため、推論システム用の仮想環境を構築しつつ、新旧どちらのPythonでも扱えるjsonファイルでデータのやり取りを行なうようにした。
この仮想環境には、開発側でPythonモジュールを事前に用意しておけるため、プロジェクト側で改めて用意する必要がなく、環境やバージョンの違いによる不具合が減少するメリットもある。

また、j機械学習の推論システムでは最後に中間アニメーションデータを出力する際にjsonファイルにすることで、Mayaに直接出力できるというファイル側のメリットがあった。

また、ゲームの開発が進んで新規キャラクターが実装される場合にも、学習モデル内のものとボーン構造が一致していれば、初期ポーズとなる“バインドポーズ”を登録するだけで自動生成が可能になる。訓練データがない新規キャラクターでも、問題なく動作するわけだ。


ほかにも、ポーズウェイトを記録して出力する“Lsdml”データでは、毎フレームごとのLipmapのポーズウェイトを格納している。ボーンアニメーション出力よりもクオリティーは少し下がるものの、この仕様によりHSFに近い従来通りのワークフローを実現し、ほかの骨構造のモデルへの適用も可能という、汎用性の高い方式になっている。
さらにこのLsdmlをUnreal Engineで再生するためのプラグインも開発されており、汎用性をさらに広げている。

ツールとしての課題も、当然ある。現状、出力されるデータがフレームごとのため、効率のいい編集手段が求められている。また、笑顔の際に口角を上げるなどといった指定から生成することができないため、感情ごとのLipmapがあることを活かし、機械学習と連携させるシステムの研究が必要とも考えているという。

機械学習の詳細を解説。まだまだ研究の余地あり
引き続き、レアンドロ氏からLip-Sync MLでの機械学習の詳細が解説された。非常に複雑かつ長大な工程なので、そのつもりでご一読いただきたい。
まずはすべてのスタートとなる“訓練データ”について。訓練データとして『FF7 リメイク』カットシーンから抽出された音声と、それに同期したリップシンクアニメーションを準備したという。
多数のデータが2秒程度の短いものばかりで、長いデータとの差異が生じかねないという問題もあったが、近似データを連結することでこの問題は解決した。

さらに音声の速度や異なるキャラクターによるピッチの変化に対し、ロバスト性(外部の要因に影響されにくい性質)を向上させるためにいくつかのデータ拡張を実施。ランダムで速度やピッチを変化させたクリップを、訓練データに混ぜていった。
そうして用意した訓練データは、ふたつの分離したサブモデルを通じて学習させていく。まず“音声モデル”が生のオーディオと任意の言語のスタイル情報を入力し、それらを処理して“音声特徴量”と呼ばれるデータを生成する。そしてつぎの“リグモデル”が音声特徴量やスタイル情報、リグやキャラクターのバインドポーズを入力として受け取り、さまざまなアニメーションを出力する。
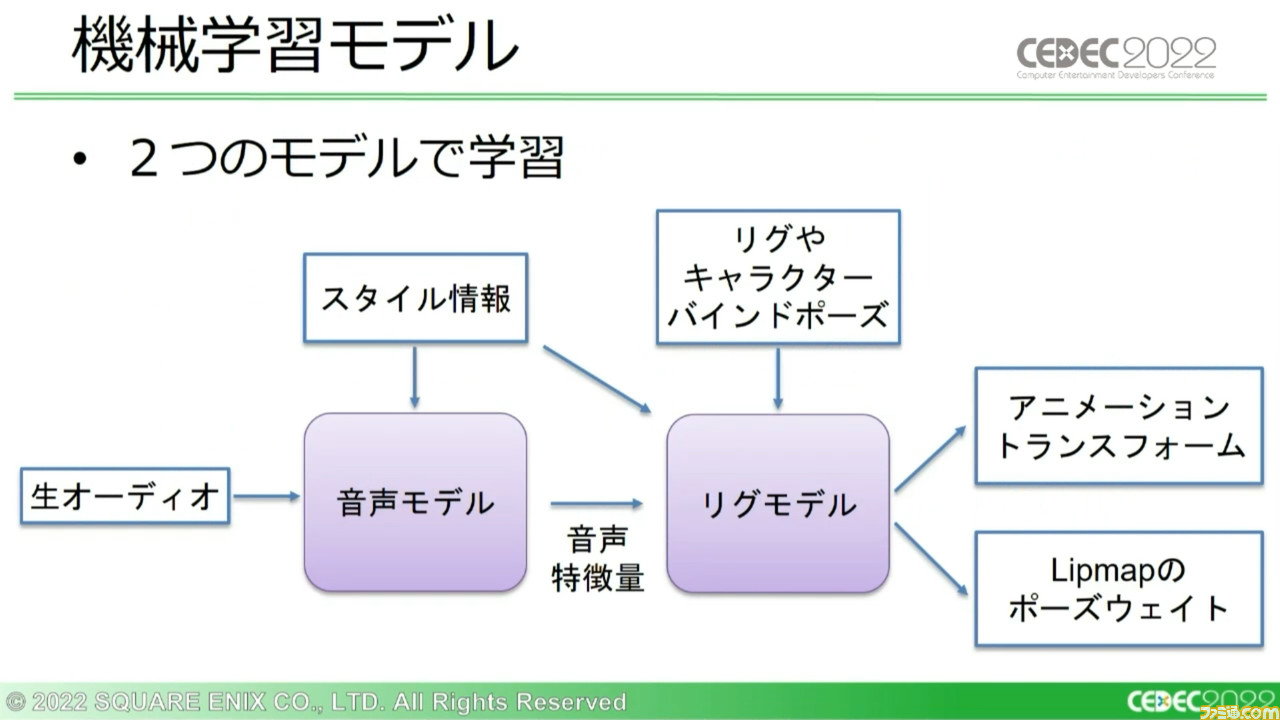
このサブモデルがどう動くのか、その詳細も解説された。音声モデルは生のオーディオ信号をモノラルに変換し、19.2kHzにリサンプリングする。一般的なレートではないのは、アニメーションフレームと音声サンプルとの適切な同期を確実にするためだ。

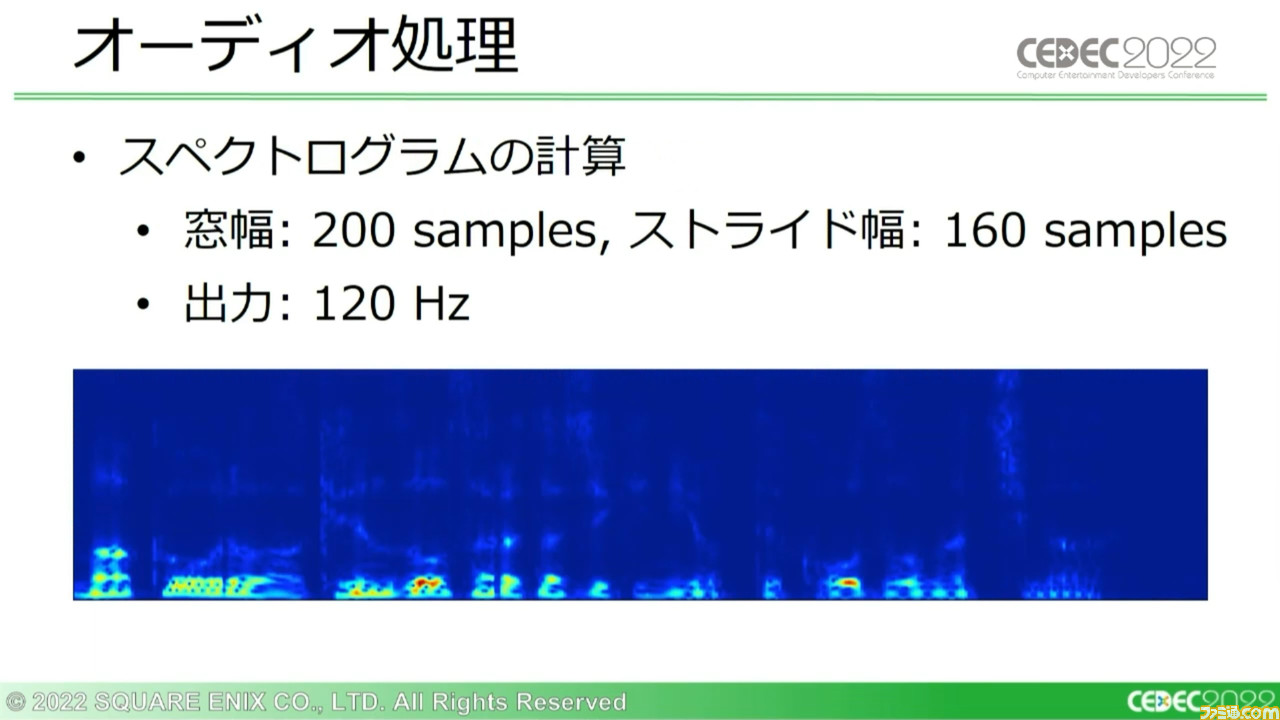
このリサンプリングデータを、つぎに短時間フーリエ変換によってスペクロトグラム(※)に変換し、周波数ごとの強さを計算する。サンプリングレートが19.2kHz、ストライド幅が160であるため、この処理では1秒間のオーディオにつき120の出力が生成される。
※スペクトログラム:周波数分析の結果から生成される、信号成分の強さを色により表したグラフ。これにより強さ、周波数、時間の3次元から、音声の解析結果を表示できる。日本では“声紋”と呼ばれる。
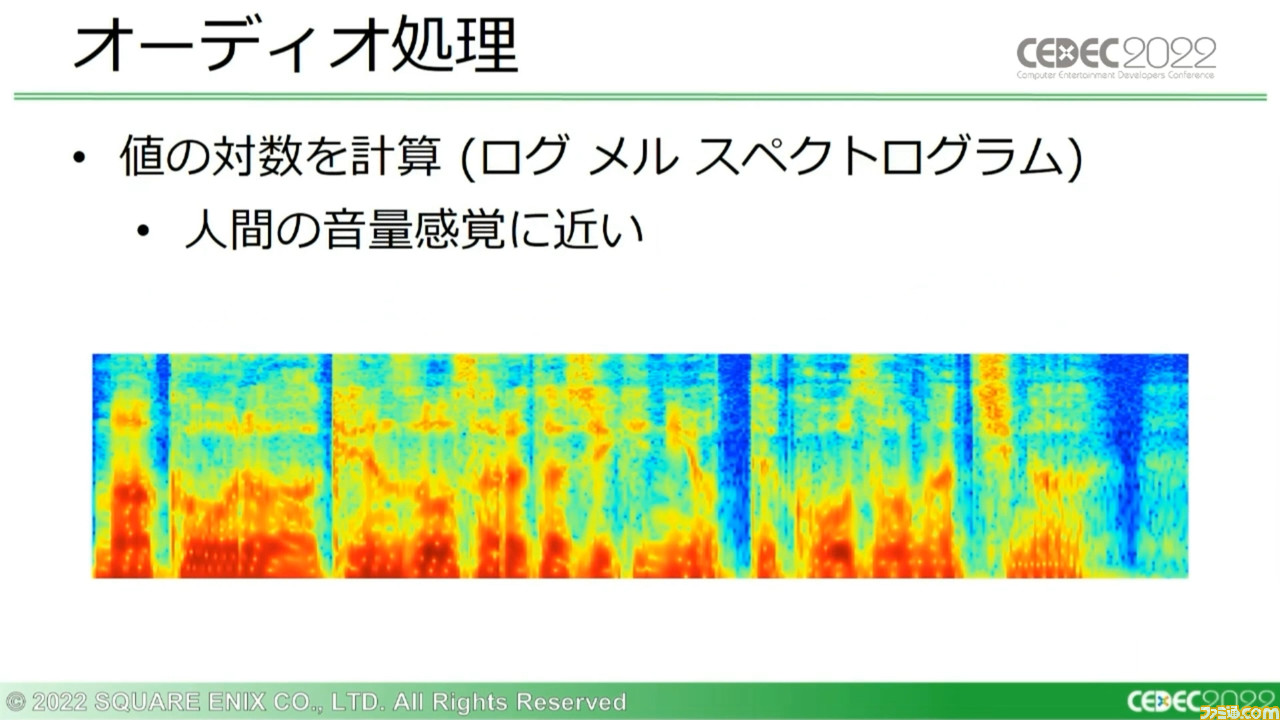
さらにこのスペクトログラムをより人間の周波数感覚に近い“メル尺度”に変換し、“メル スペクトログラム”を生成する。グラフ内の縦方向の変化に音声ピッチの変化がよりよく表れるなど、この生成にはいくつかのメリットがある。
さらにこのメル スペクトログラムから値の対数を計算することで“ログ メル スペクロトグラム”を生成。より人間の音量感覚に近いグラフが形成される。

続いてこのログ メル スペクトログラムに、画像処理技術を適用していく。このグラフ画像の水平方向はオーディオの時間の変更を、垂直方向は近似的なピッチ変更を意味するようになっている。
この処理ではまず、時間とピッチの両方で不変である“特徴量”を学習するために、畳み込みニューラルネットワーク(※)を用いて画像を認識・学習させる。グラフ画像から相対ピッチ(ほかの音との相対的な音程の差異で認識される音の高低)を読み取ることで、絶対的な周波数の値そのものよりも、周波数間の関係について出力していく。
※畳み込みニューラルネットワーク:AIに深層学習を促す手法のひとつで、画像認識に特化したもの。画像を複数層の組み合わせで学習していき、最終的にはすべての層を結合して出力に至る。
それと並行し、画像の各列に単純な処理も実行。画像の全結合レイヤーから絶対ピッチ(周辺の音に影響されない絶対的な音程。特定の周波数と相応している)を導き出し、出力する。このふたつの出力が、さらに別の処理に送られていく。
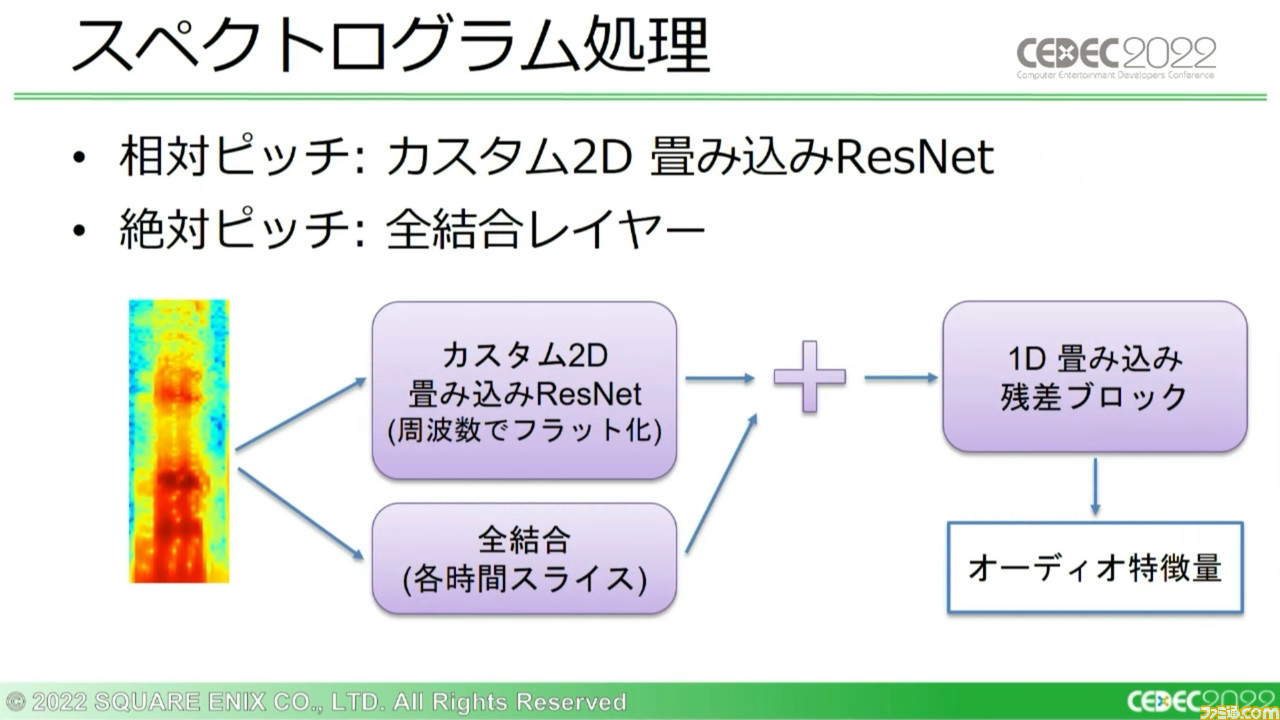
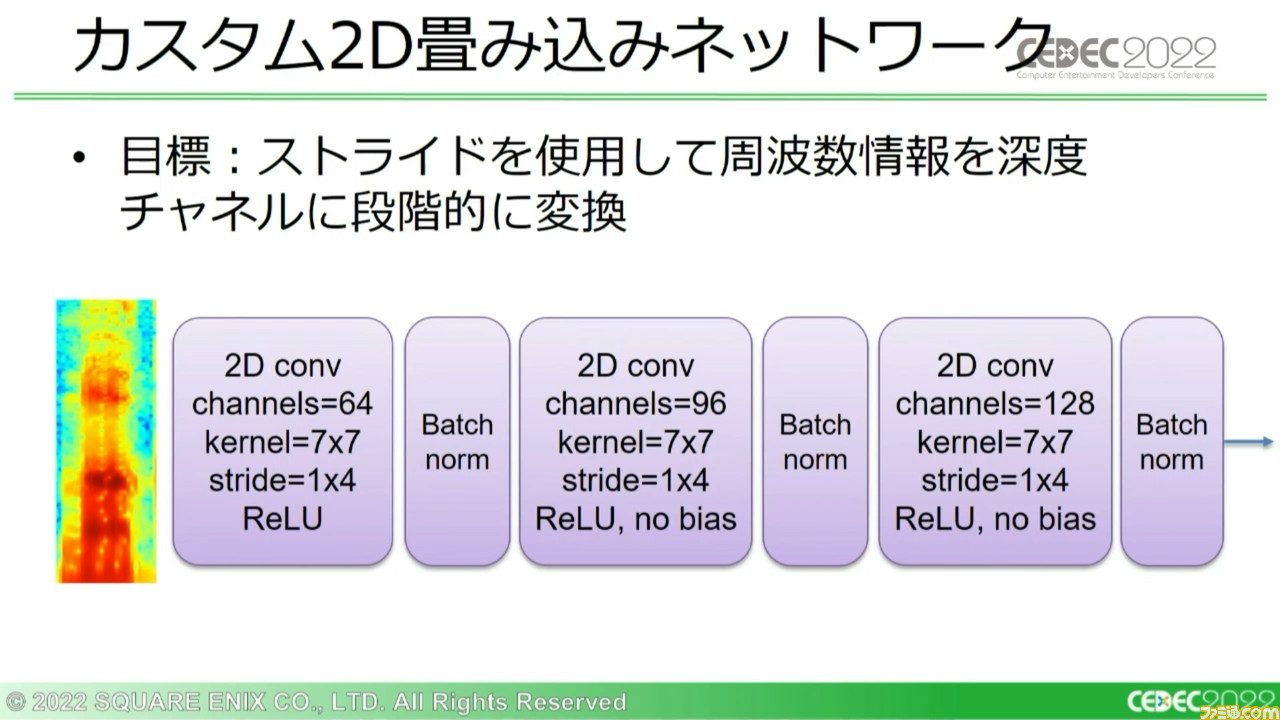
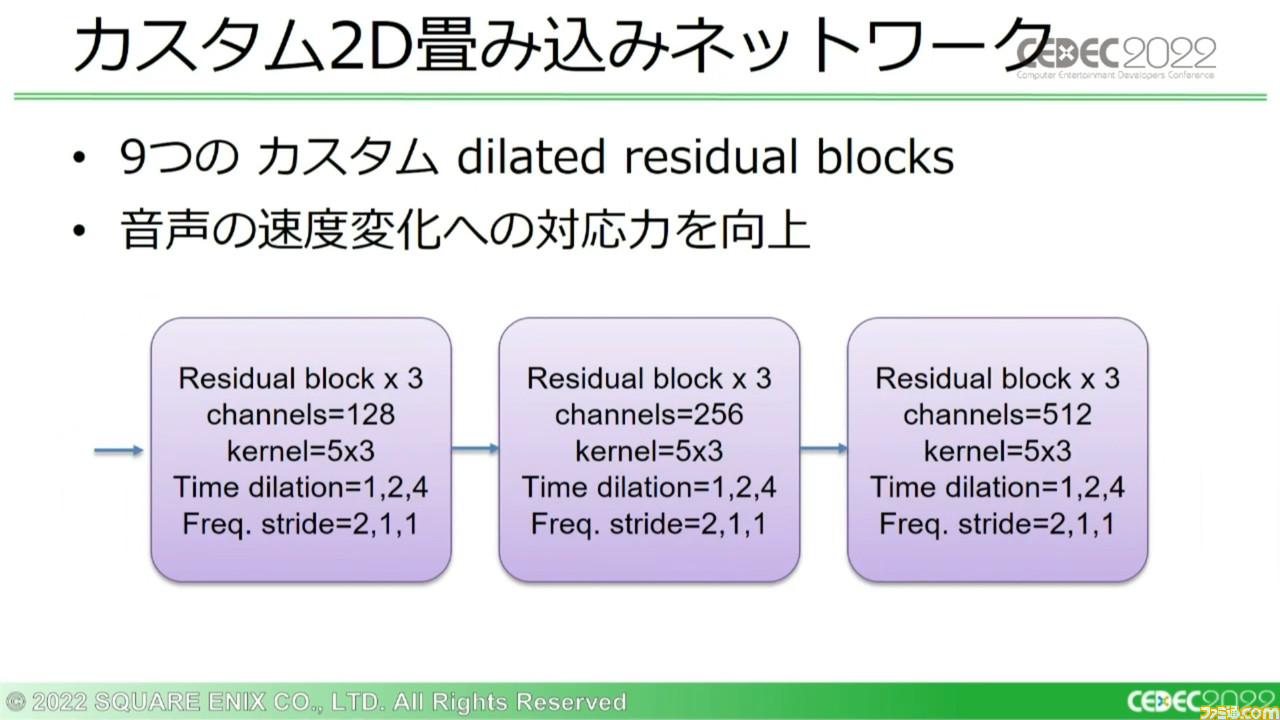
このシステム上で使用している二次元畳み込みネットワークは、時間で変化する一次元の出力を生成する。こう書くと難しいが、要するにスペクトログラムの画像の“高さ”を段階的に縮めていくのだ。
さらに音声変化により適応できるように3つのカスタム残差ブロックを3セット用意し、9つのブロックで対応。これらのカスタムブロックのセットはチャネルの深さを倍にする一方で、画像の高さを半分に削減していく。
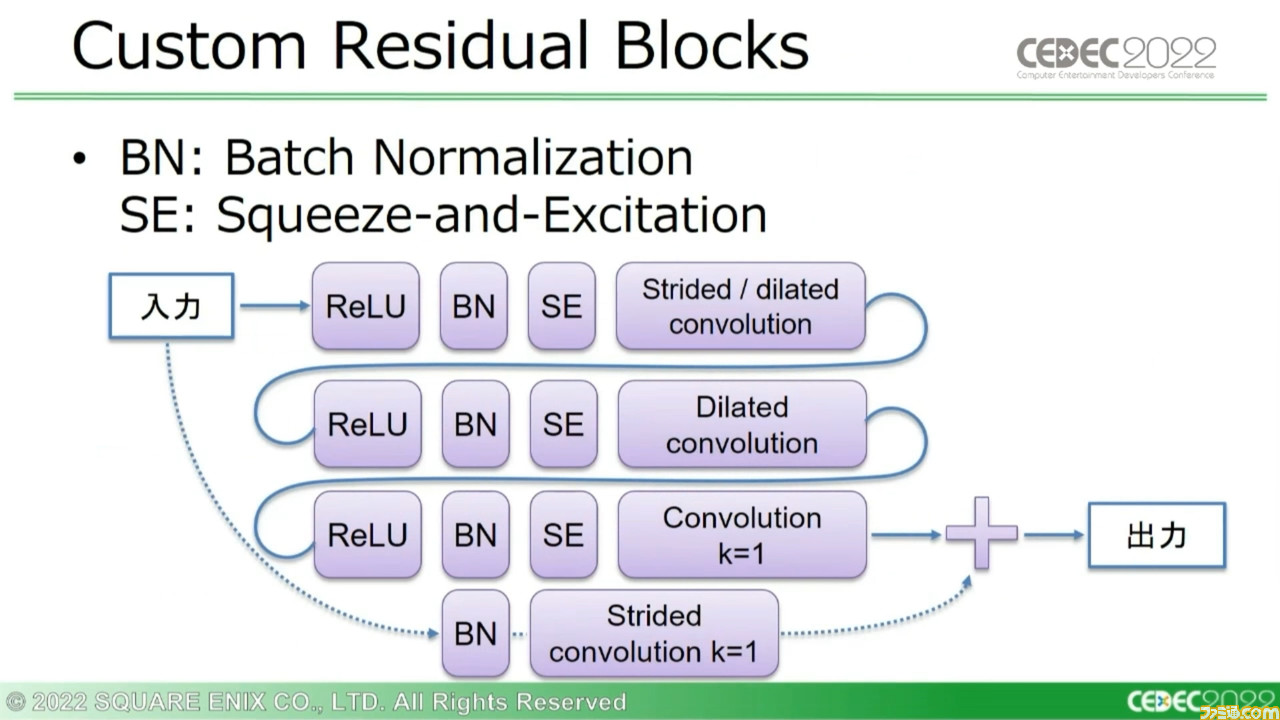
相対ピッチと絶対ピッチの結合については、先ほどの説明にもあった残差ブロックによる処理を適用する。この結果、“オーディオ特徴量”のデータが出力される。この出力を言語スタイル情報に基づいて正規化し、単一のトランスファーエンコーダーに相対位置埋め込みの学習結果を反映させ、音声モデルの出力である“音声特徴量”を生み出す。
スタイル情報については、『FF7 リメイク』においては言語や53名のキャラクターの違いなどを値にしたものとなっており、システム上ではスタイルならびにスタイル値ごとに埋め込みを学習していく。学習には複数の埋め込みを組として足し合わせた値を使うほか、値が0の場合は言語スタイル事態を埋め込みとして使用する。
また、スタイル値の埋め込みは0に初期化される仕様のため、訓練データのサンプルが少ないスタイルは、スタイル値が設定されない場合の一般的な結果に近づいていく。
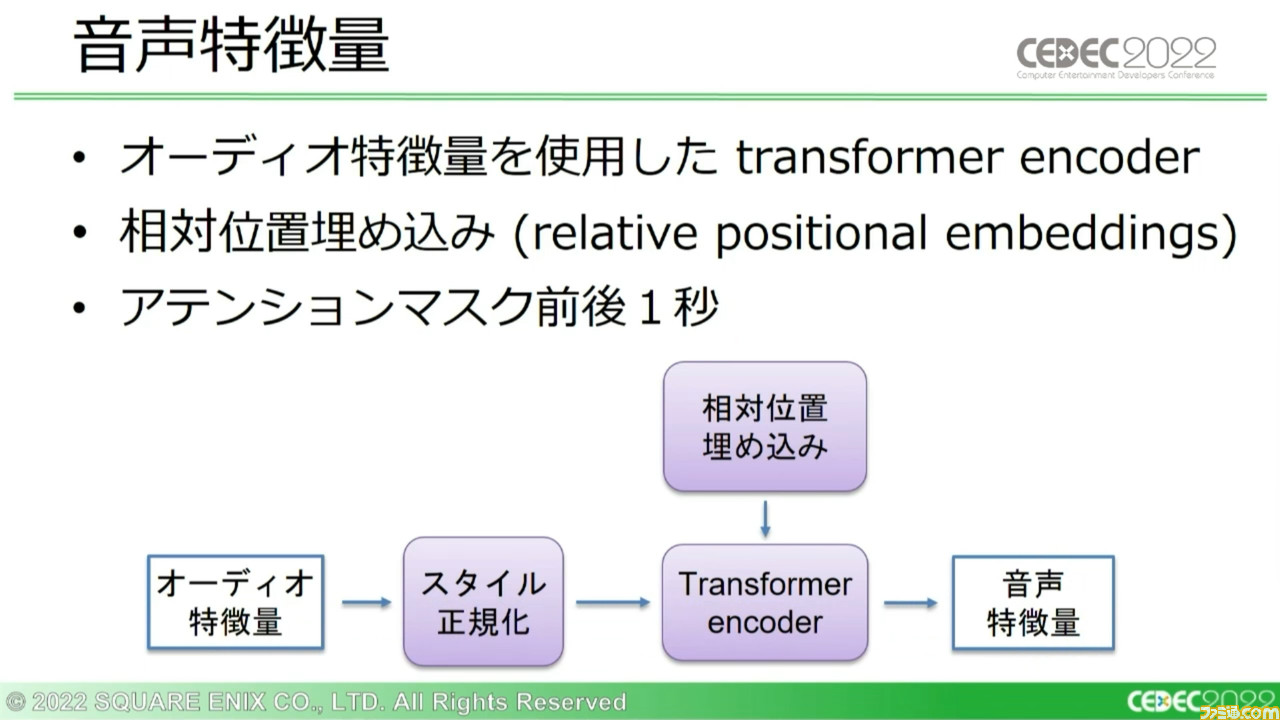

こうして得たスタイルの埋め込み情報の集合は、“Multi-head attention”で合成。それらは同一サイズのスケールベクトルとバイアスベクトルに分けられ、正規化に使用される。
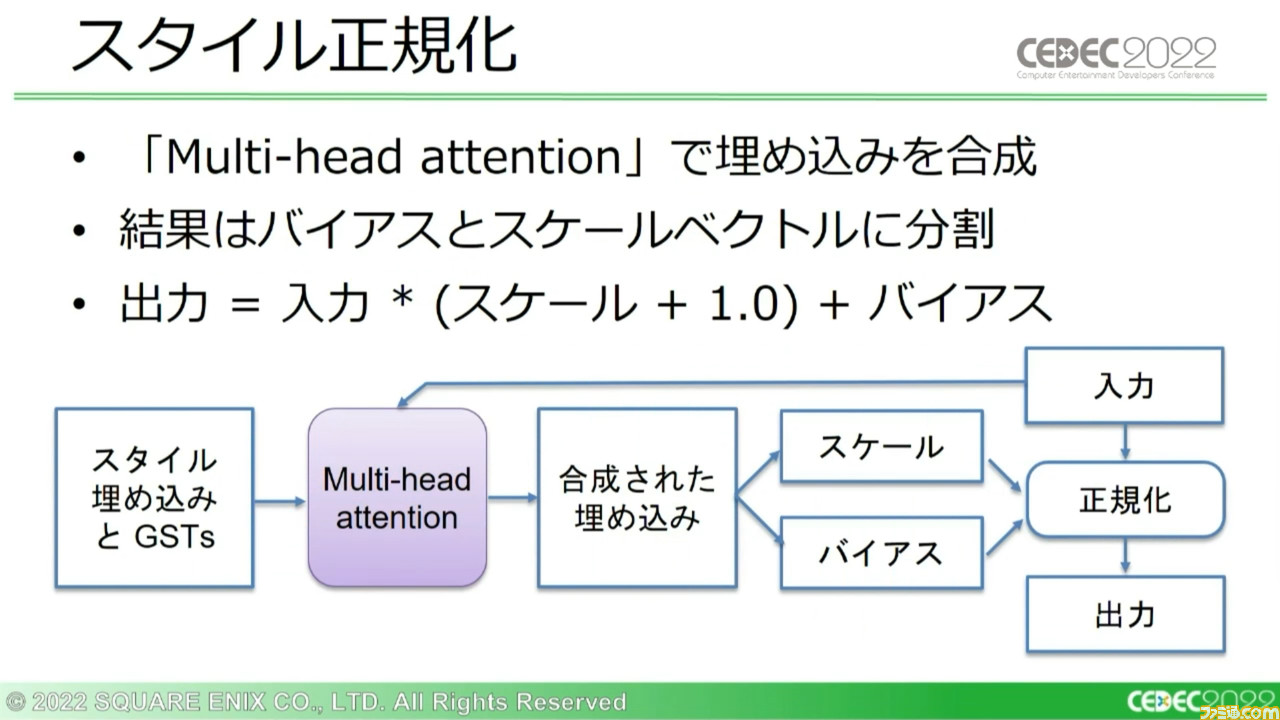
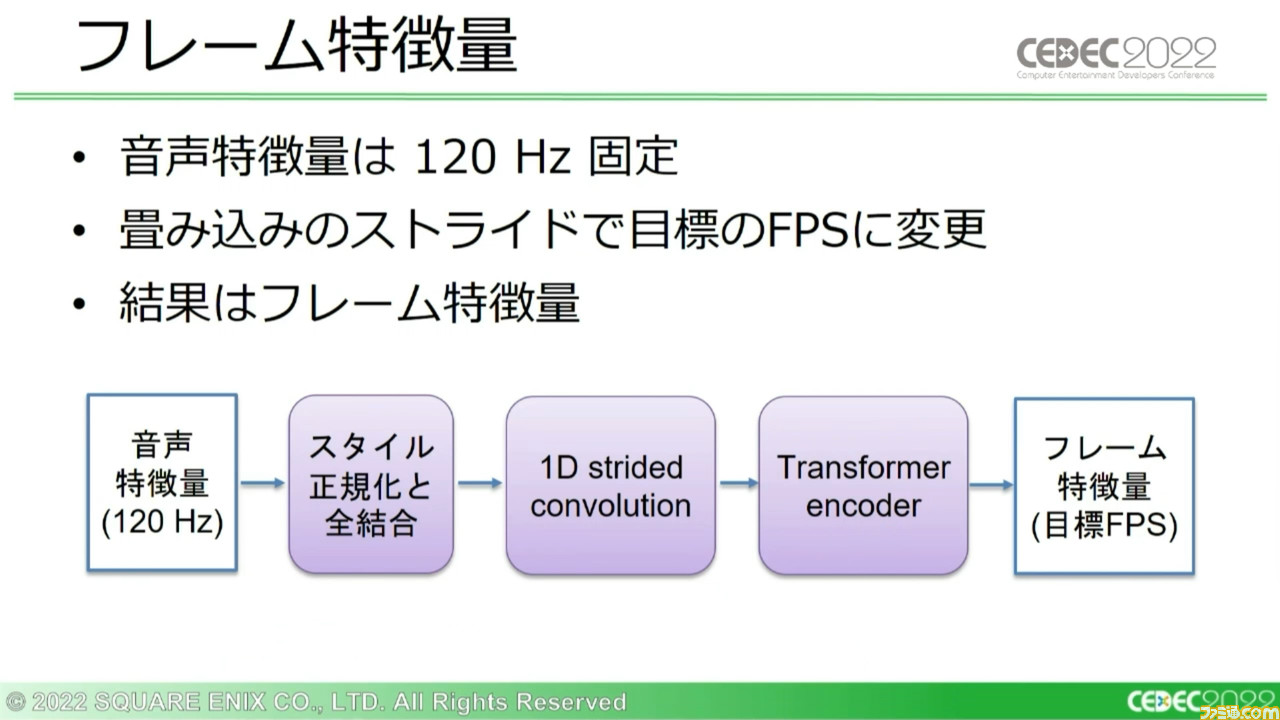
続いて、リグモデルの動作について。リグモデルでは音声特徴量に使用可能なすべてのスタイル情報で正規化を行なう。なお、ここではスケールベクトルのみを使用する。バイアスベクトルを使用すると、結果が悪化するという実験結果があるからだ。
さらに全レイヤーを結合後、120Hzで固定されている音声特徴量の周波数をダウンスケールし、アニメーションのFPSに合わせる。さらにTransformer encoderを適用することで、“フレーム特徴量”が出力される。
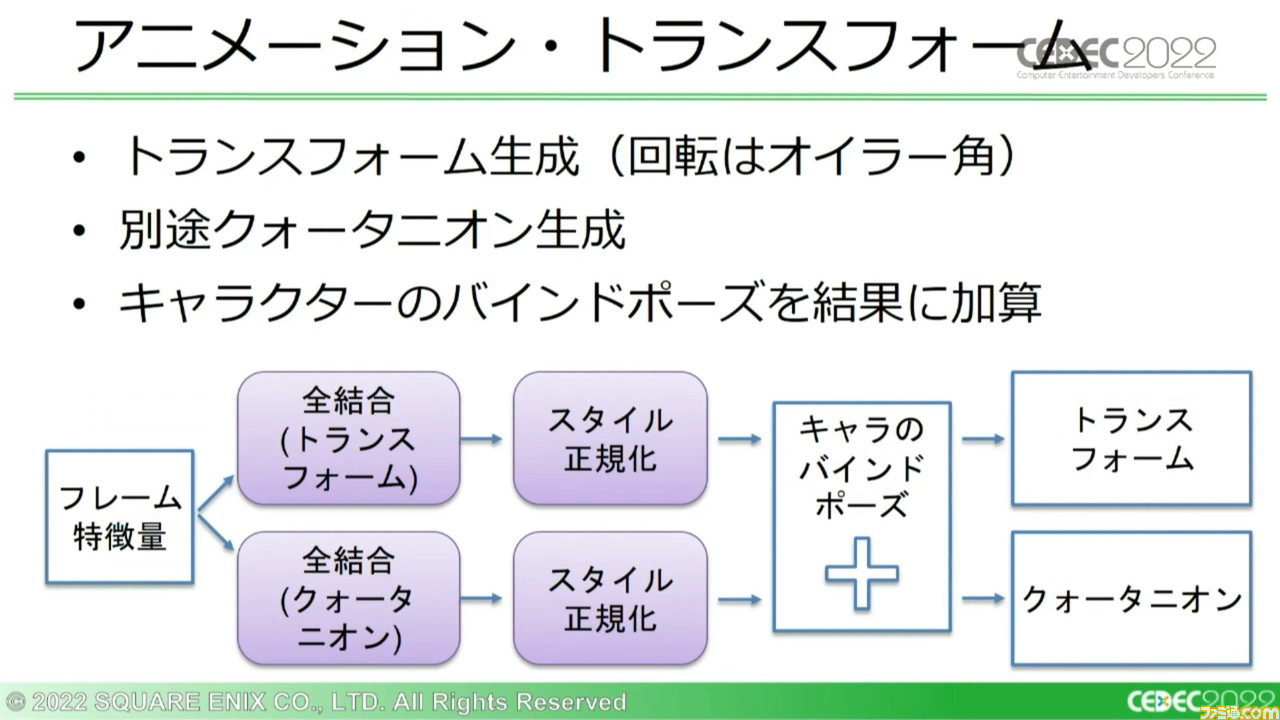
このフレーム特徴量から、複数種類の出力が生成される。ひとつ目はアニメーショントランスフォームの直接出力。これはクオリティーがもっとも高い結果が生成されてカットシーンで使用されることを想定しており、フレームごとに口の変形情報を生成するため、データ量が大きい。
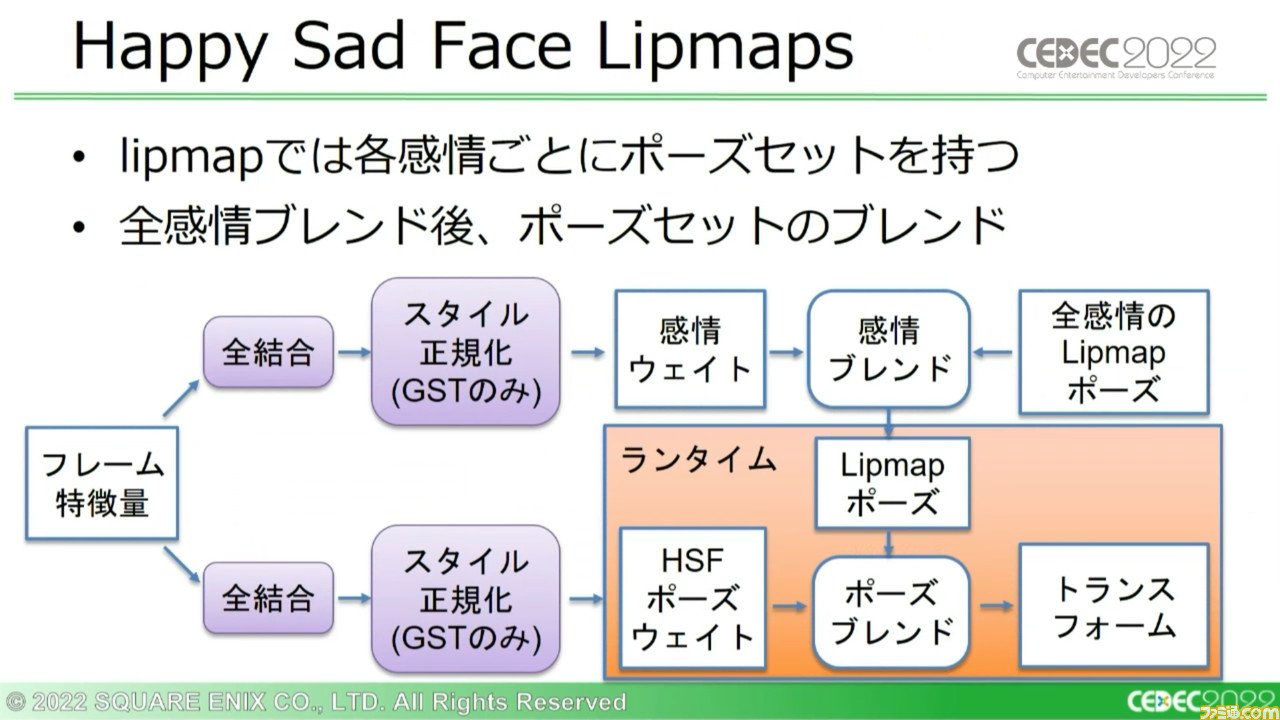
さらにこれらと同時に、フレーム特徴量からはHSFのLimmapポーズウェイトも出力される。この際には、モデル推論時の処理とゲーム内のランタイム処理が分けられており、前者でLipmapのポーズウェイトを生成・保存、後者でこれらのウェイトとLipmapのポーズをロードし、ブレンドしてアニメーショントランスフォームを得る。
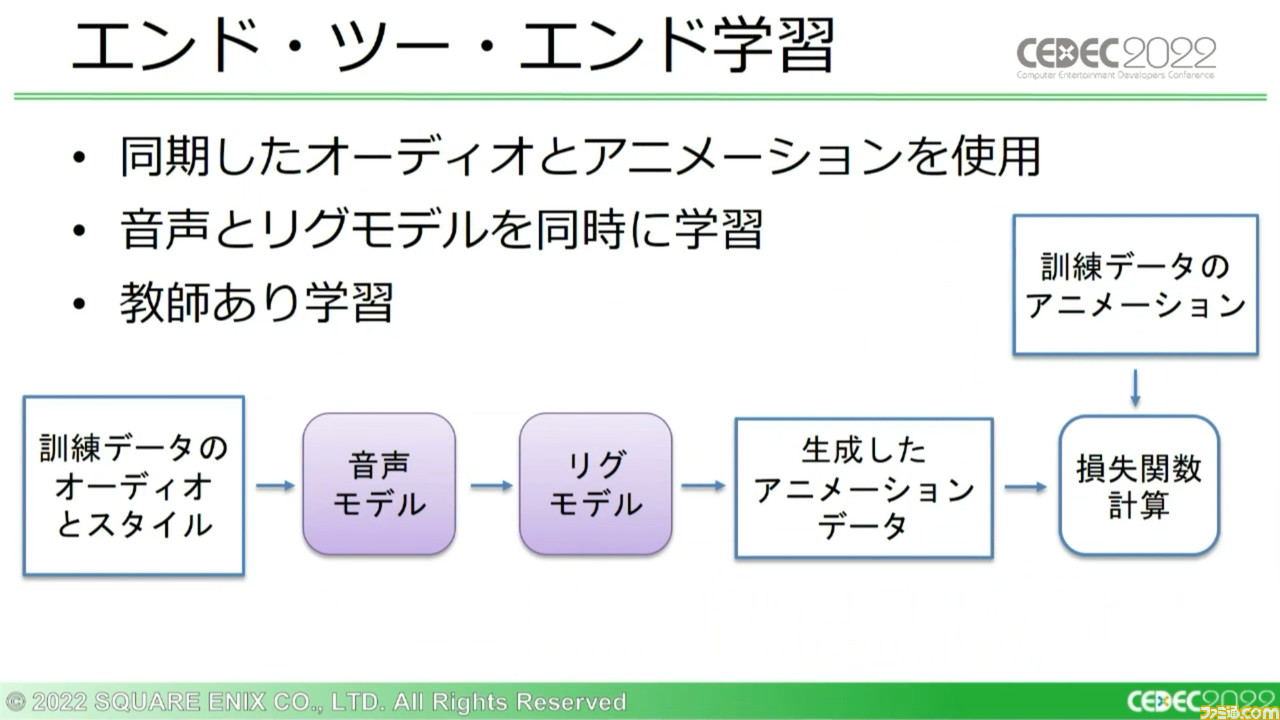
最後に、学習の方法について。開発チームで使用している学習方法はふたつあり、ひとつは“エンド・ツー・エンド学習”。同期したオーディオとアニメーションデータを用いて音声モデル、リグモデルの両方を同時に学習させ、一般的な教師あり学習アプローチを使用する。
この方法の問題は、ボーンのトランスフォームにあるすべての要素が同じ数値の範囲を持つわけではないため、移動の誤差がオイラー角の範囲を逸脱したりと、小さな誤差であっても大きな影響を及ぼすことがある点だ。これらを含め、さまざまな出力時の誤差問題を回避して汎用性を確保するために、損失関数においては単純に訓練データで出てくるボーンのトランスフォームの数値範囲で出力を正規化している。これだけでも、結果にはっきりわかる効果が見られたとのこと。

もうひとつの学習方法は、自己教師ありの“音声モデルの事前学習”だ。リグモテルの学習のために、事前学習された音声モデルを使用していく。
音声モデルの事前学習には、オープンドメインの豊富なオーディオがそのまま使用でき、実際に約2000時間分ものオーディオデータセットを作成したという。訓練データをかなりの桁数で拡張できたほか、この事前学習した音声モデルはプロジェクトをまたいで再利用できる可能性がある。
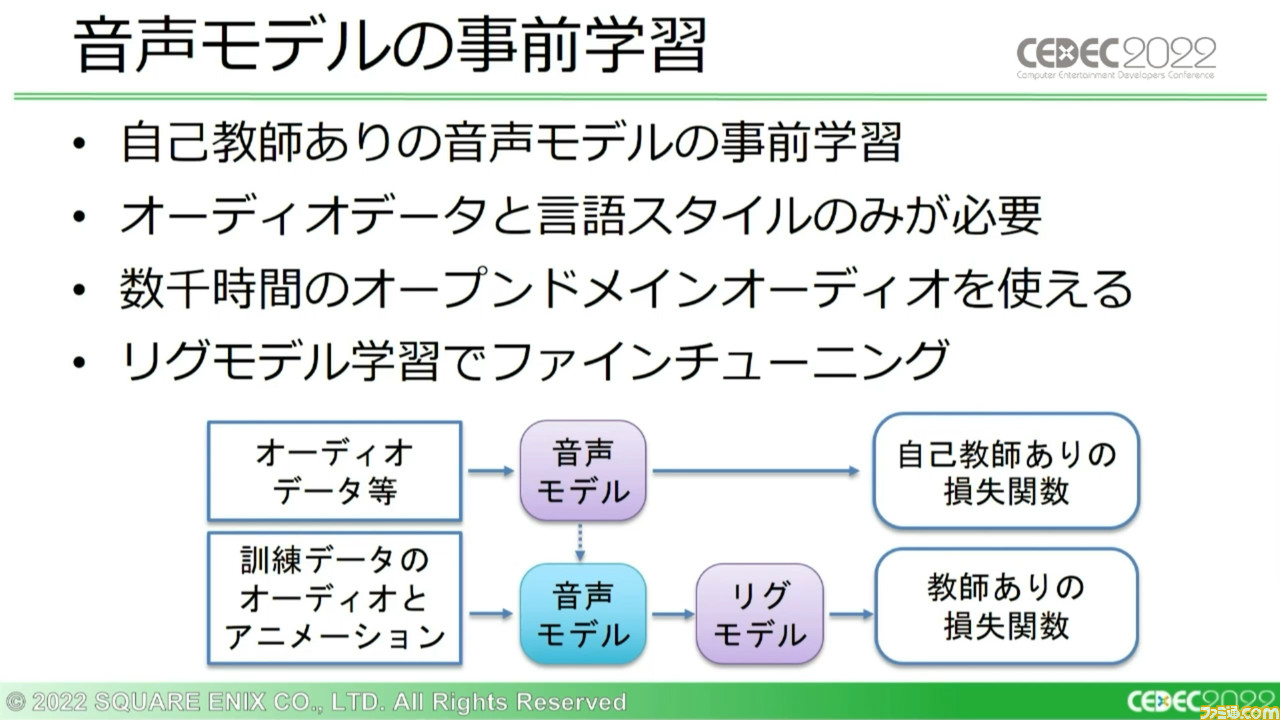
ただし、このアイデアを機能させるには課題も伴う。音声モデルの事前学習のために多くの自己教師あり損失関数を試したが、エンド・ツー・エンド学習よりいい結果は得られなかったという。それでも、今後もこの学習方法には大きな可能性があるとして、調査は続行していくとのことだ。

Lip-Sync MLの運用事例を紹介。準備に必要だったものとは
講演ではシステム詳細の解説に続き、実際にLip-Sync MLを運用したプロジェクトの事例について紹介された。こちらのプロジェクトの目標は、『FF7 リメイク』のアセットを使用することで次世代に向けたよりいい品質とパイプラインを検討することと、ボイス収録時に追加されるアドリブボイスについて、品質が落ちる問題を解決することだ。

HSFはテキストから使用する音素を列挙し、ボイスに合わせて並べる仕様になっている。つまり、テキストにない笑い声やため息との相性が悪く、ニュアンスの読み間違えによる問題も発生する。
こうなるとコンバート用のテキストを用意するしか対応手段はないが、大量のアドリブボイスへの手動対応が多すぎるなど、問題があまりに多かった。



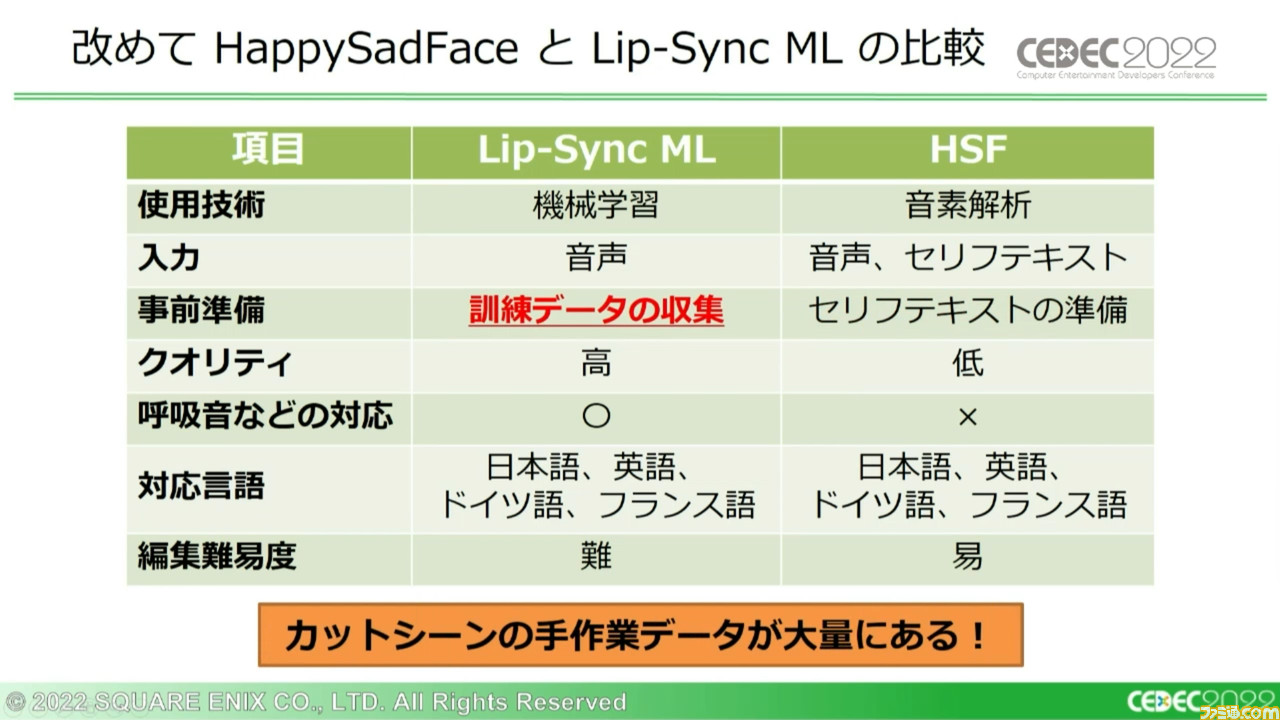
課題としてテクノロジー推進部と共有した結果、テキストの用意がどうやっても厳しいという結論になった。そこでテキスト問題から逃れるために方針を変更し、Lip-Sync MLの開発を進めることになったという。
Lip-Sync MLではテキストの準備が必要ない代わりに、大量の訓練データの収集が事前に必要となる。この点においては『FF7 リメイク』のカットシーンの手作業データが大量にあったため、機械学習に問題はなかった。
また、コンバートにはボイスとリグが必要だが、リグについてもMayaシーンファイルをそのまま使用できた。学習モデルの準備と調整はその専門性の高さから、テクノロジー推進部に任せることとなった。

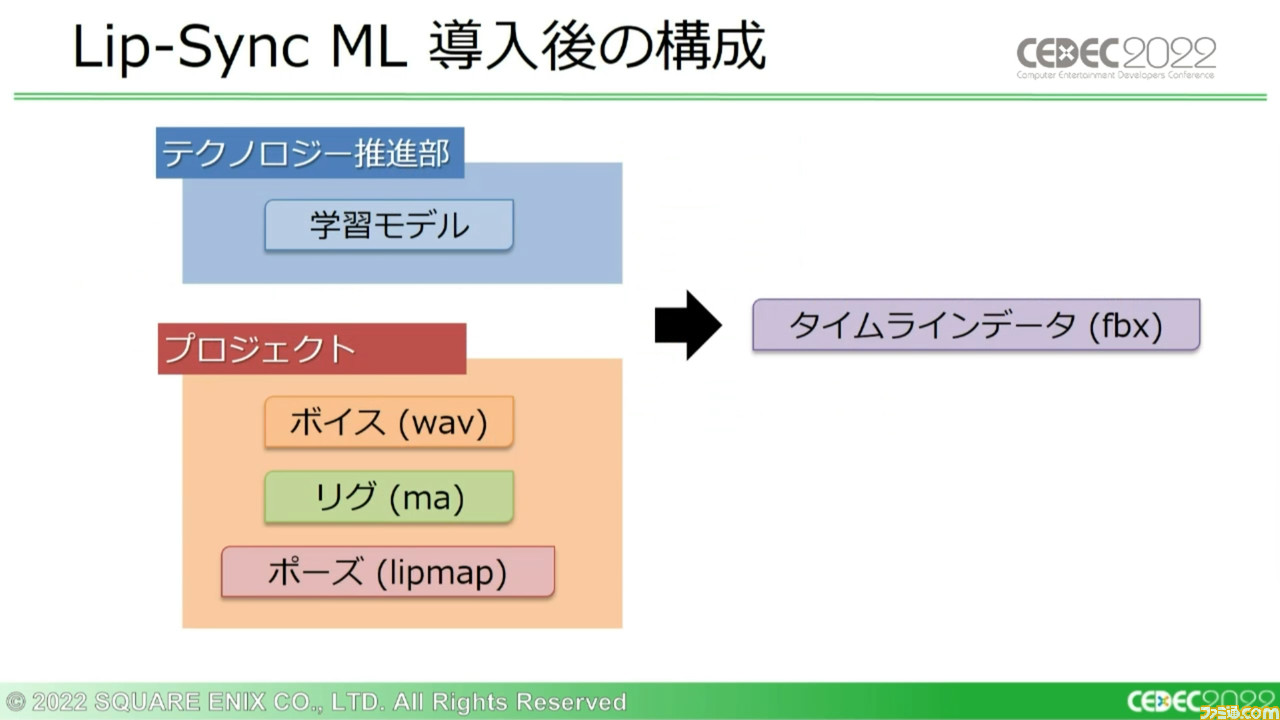
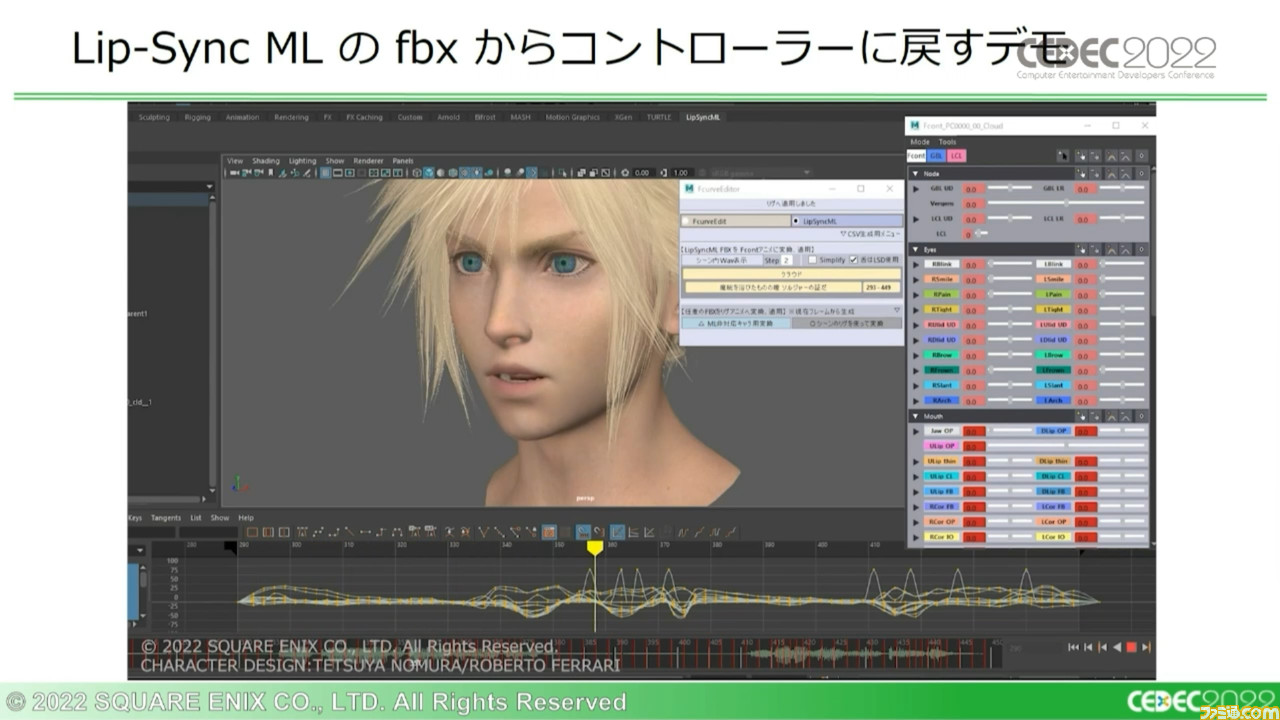
Lip-Sync MLの導入後には、手作業による部分にもハイクオリティーの自動生成データをフィードバックできるようになった。カットシーンにおいてはfbxをMayaにインポートすることで作業効率を上げられたが、カットシーン以外で課題が残った。
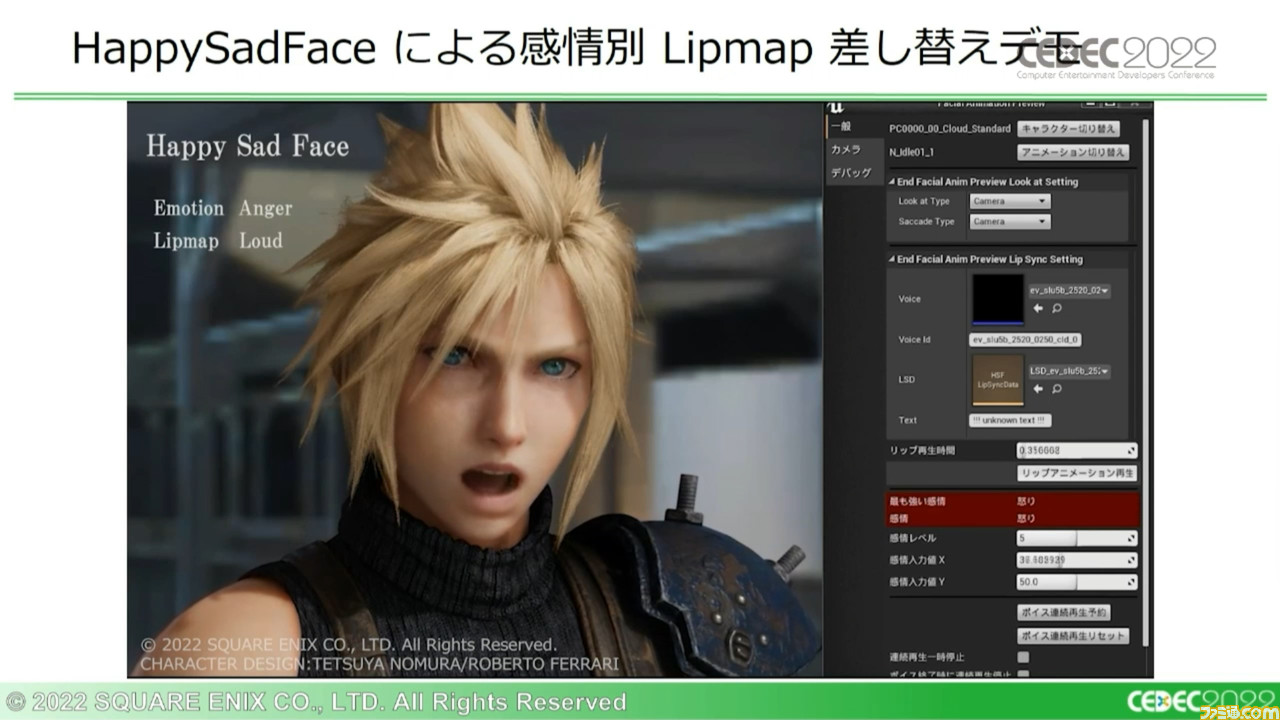
HSFはタイムラインデータがポーズウェイトのため、ポーズアセットの差し替えで形状の変更が可能だった。これを利用することで、音声から感情解析した結果を形状に反映し、表情を分けた出力を実現できていた。
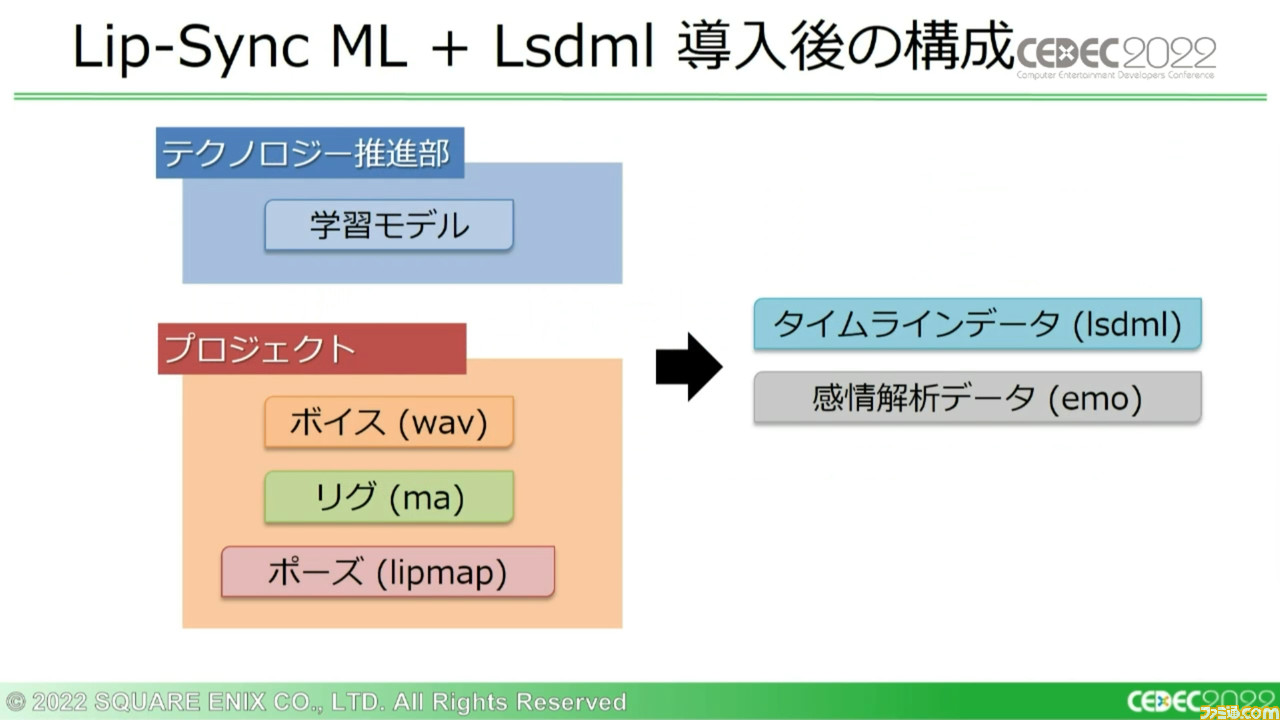
これに対してLip-Sync MLは、当初はベイクされた形状データを出力していた。このためfbxをもとに、ポーズウェイトとしてLsdmlというタイムラインデータを生成できる機能が追加されることとなった。
ポーズウェイトである以上、品質としては最大とは言えないが、感情による出し分けやイテレーション効率を考えれば、補うには余りある。
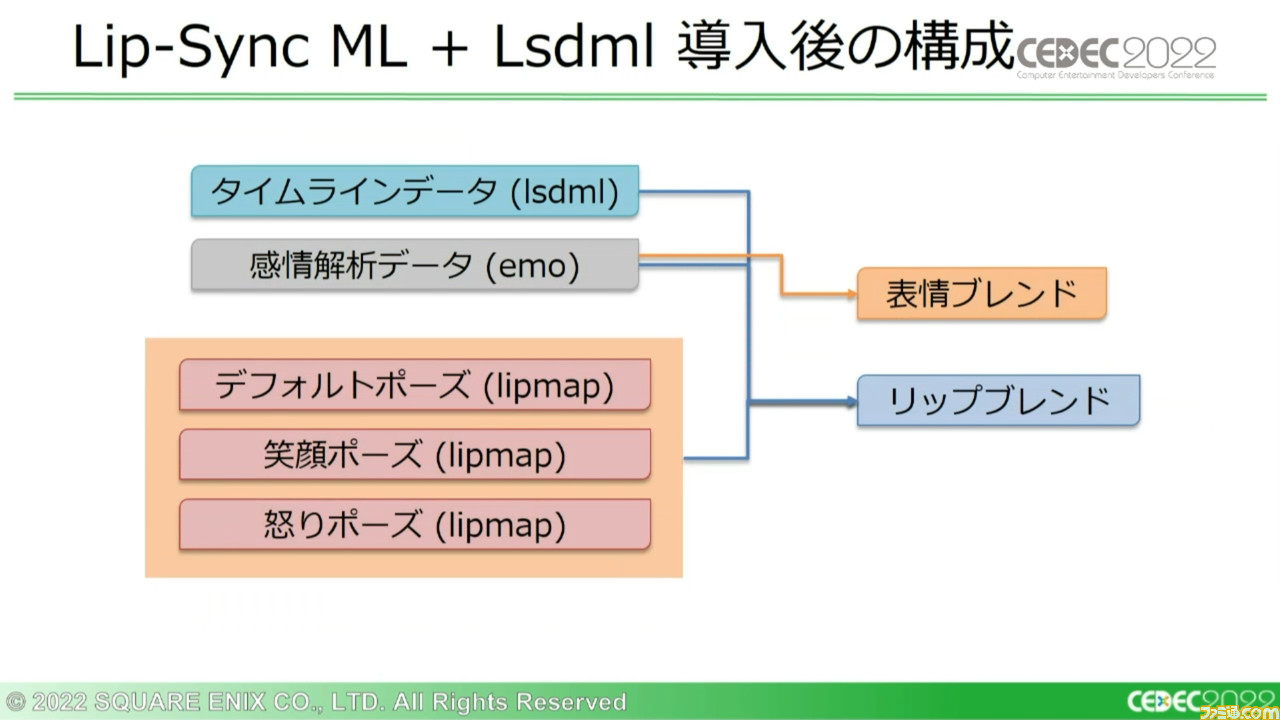

こうしてHSFのみを使用する際の課題はすべて解決したものの、新たな課題も浮上した。だがそれらも、アセットのコンバートパイプラインの改善によって解決できた。

Lip-Sync MLは学習モデルに依存した品質となり、後から出力結果に調整を入れるのが難しい。反面、HSFはタイムラインデータをMayaで直感的に調整しやすいため、手動調整の場合はHSFを使用したいという場面が多い。
この両者の強みを活かすべく、中間データをそれぞれ別形式で用意するアセット構成が提案された。

Unreal Engineは、uassetインポートデータにインポート元となる中間データを複数持たせることができ、個別のハッシュ値が保存されるため、中間データごとに比較が可能となっている。
さらにuassetに、HSFとLsdmlのどちらを使うかを決定するフラグを追加。デフォルトではLsdmlを適用し、アーティストが手動調整したい場合はHSFを選べるようになった。

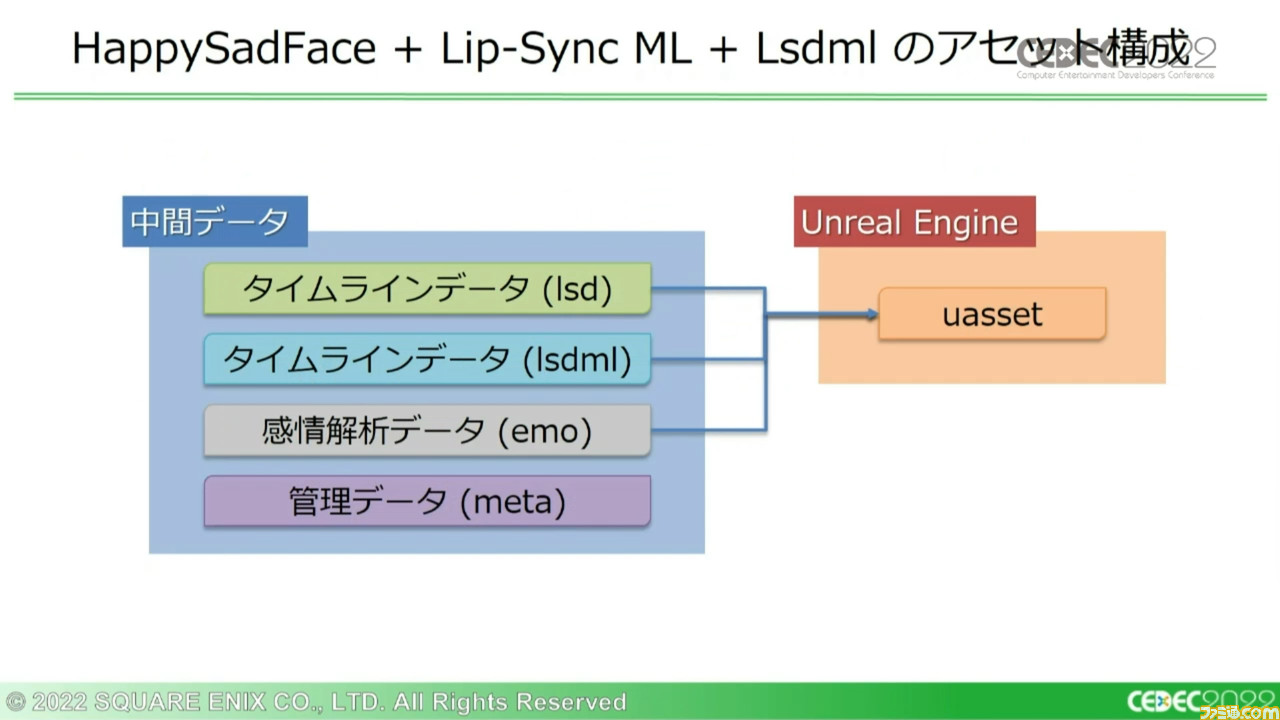
中間データを複数持つ(uassetをひとつにする)ことには、ほかにも利点があった。ゲーム側からはHSFとLsdmlのどちらを使用するかを認識する必要がなく、アニメーターが置き換えなどをしたとしても、アセットの読み分けは変わらないため想定外のことは起きにくい。
また、中間データのいずれかが更新されるとハッシュ値チェックでその更新を検出でき、再インポートを定期的に実行して最新状態を保てるようになる。

中間データのコンバート時間についても、ハッシュ値チェックによる検出が役立つ。更新があるデータのみを検出できるようになるため、コンバートにかかる時間が劇的に短縮できるわけだ。また、ハッシュ値の末尾に情報を追加することで、学習モデル変更時の一括再コンバートなどにも対応できる。


次世代システム導入のためには、入念な準備を
講演の最後の、全体のまとめについては下画像の通り。テキスト入力を必要としないリップシンクアニメーション生成システムを求める声に対して、それだけに留まらない次世代の技術と環境があれよあれよという間に実現したことに、要望した側も大いに驚き感動したという。

今回の講演では、最新の機械学習ツールにおいてもその開発におけるトライ&エラーはもちろん、その運用と学習のためのさまざまな準備と環境構築が重要であるという点が実例で示されたかと思う。機械学習のような最先端の技術をただ闇雲に取り入れるのではなく、今回の事例のように段階的に準備と検証を進め、これまでの体制やシステムも視野に入れていくことで、より円滑な効率化が望めるはずだ。








