2021年8月24日~26日の3日間、オンラインにて開催された日本最大のコンピュータエンターテインメント開発者向けのカンファレンス、“CEDEC2021”。本稿では、会期1日目の8月24日に行われたセッション“冴えるヒロインの作りかた ~自然言語処理AIによるキャラクター性の抽出と反映への事例紹介~”の内容をリポートする。

本セッションでは、バンダイナムコ研究所の頼展韜氏と石原健司氏が登壇。AIがいかにテキストでキャラクターの魅力を立たせるか、AIがどのようにセリフ制作現場をサポートするか、という2点について、同研究所が取り組んでいる手法や研究が紹介された。



セッションでは、まず、自然言語処理AIとそのトレンドについて解説された。自然言語処理AIとは、人間が日常的に使っている言葉(自然言語)をコンピュータに処理させ、その言葉の構造や意味を明らかにする技術のこと。この技術は近年、Google翻訳(Google Translate)や、感情認識AI、企業のお問い合わせ対応の場面で導入されているチャットボットなどで使用されており、人々の生活をサポートしてくれている。

そんな、自然言語処理AIのトレンドは、最近ではルールベース手法からディープラーニング手法へと移行していると、頼氏は説明。ルールベースとは、たとえば、感情認識AIのサービスの中で、この言葉はポジティブか、あるいはネガティブの意味を持つか、ということを判別するために、あらかじめ“どの言葉がポジティブであるか、ネガティブであるか”という辞書を作って判別する手法のこと。
対して、ディープラーニングは、ネット上に存在しているビッグデータからAIが学習することで、対象となる言葉がポジティブの意味を持つか、それともネガティブ意味を持つかを判別する手法のことで、2018年以降は、こちらの手法がトレンドとなっているそうだ。

ひととおり、自然言語処理AIとトレンドについて説明されたところで、本セッションの主役(ヒロイン)として、“ミライ小町”が紹介。彼女は、バンダイナムコスタジオ・バンダイナムコ研究所の技術研究を紹介するために生まれた、22世紀型アイドル。そんな“ミライ小町”は、昨年の“CEDEC2020”のセッションでも取り上げられており、キャラクターに適応できるさまざまな技術分野で活躍している。


先ほど紹介した、チャットボットのような汎用的な自然言語処理では、機能性や正確性が重視され、万人向けのものとなっているが、キャラクターのための自然言語処理では、フィラー(※)や呼称、語尾、内容を通じて、おもしろさやキャラクターらしさ、独自性を表現し、キャラクター(ヒロイン)を冴えさせている。
※「えっと……」など、人間の思考のあいだを埋めるための言葉。

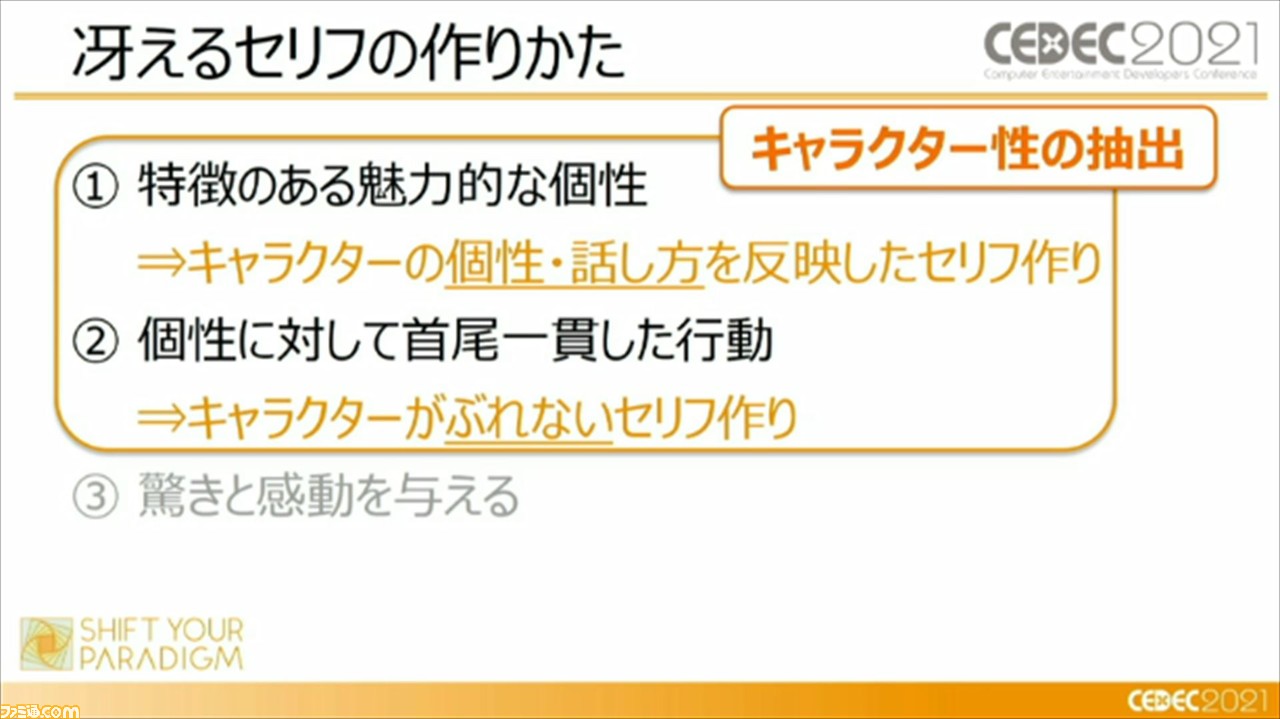
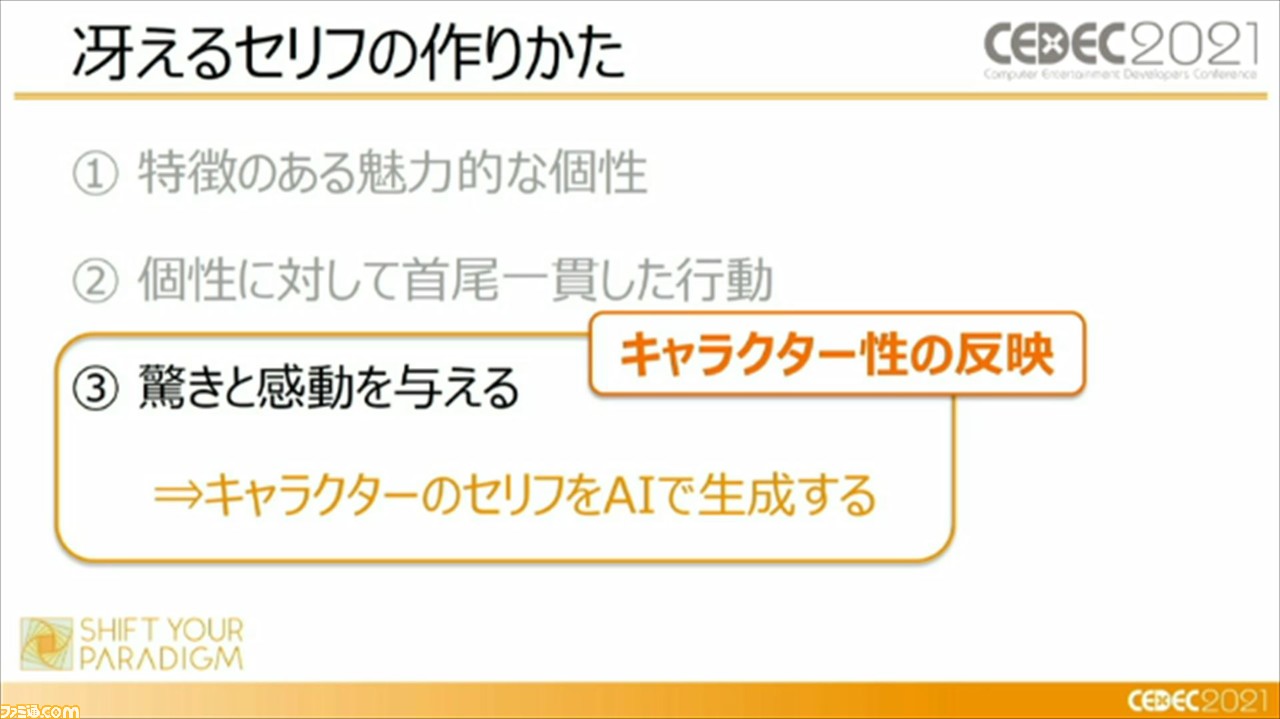
つまり、キャラクターを冴えさせるための自然言語処理のポイントとしては、“特徴のある魅力的な個性”、“個性に沿って首尾一貫した行動”、“驚きと感動を与える”の3点が重要であるとのこと。この3つのポイントを踏まえて、ディープラーニングとルールベース、2つの手法を用いて、キャラクターを冴えさせるセリフの作りかたが紹介された。

最初は、ディープラーニングを使用した、冴えるセリフの作りかたについて。キャラクター性を抽出させるには、セリフを含む個性をAIに学習させていく必要があるが、その際には、マンガやSNSなど、媒体の特徴に特化した前処理を行うことが重要であるという。たとえば、マンガではほかのキャラクターのセリフの引用など、キャラクターがぶれてしまうような要素を除外したり、SNSでは絵文字や顔文字などの感情表現にも気を使っていく必要がある。

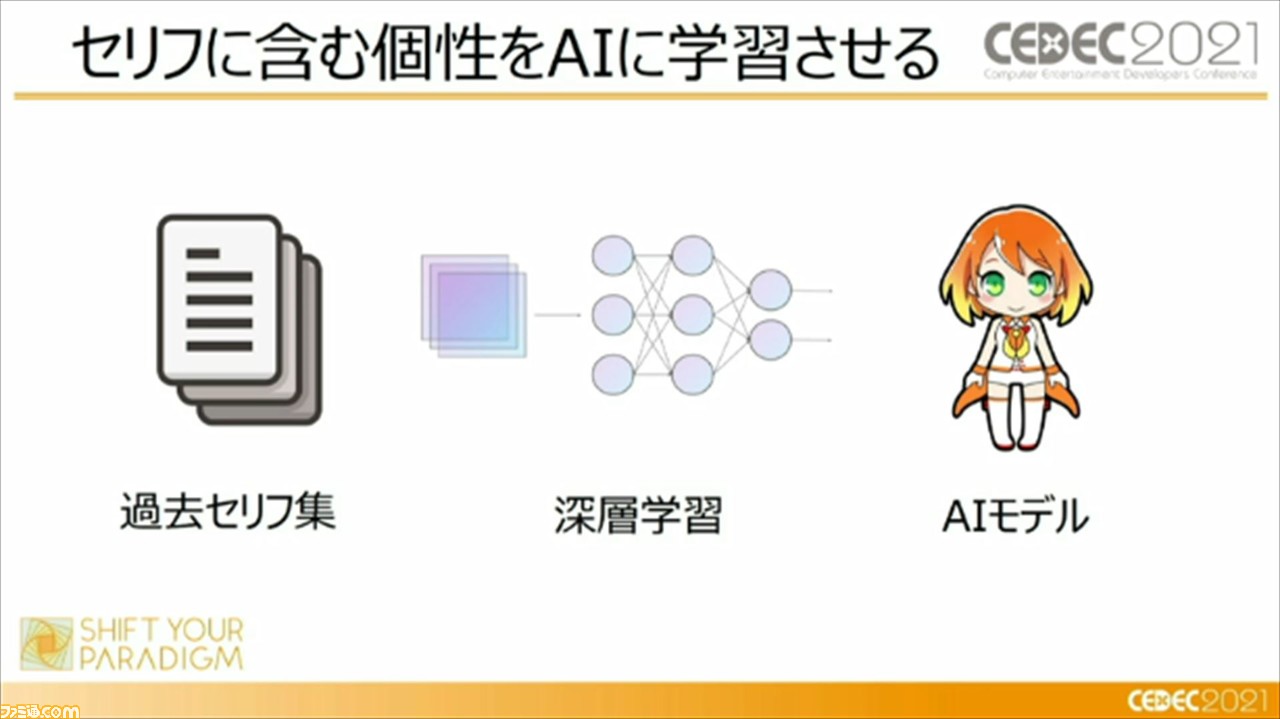
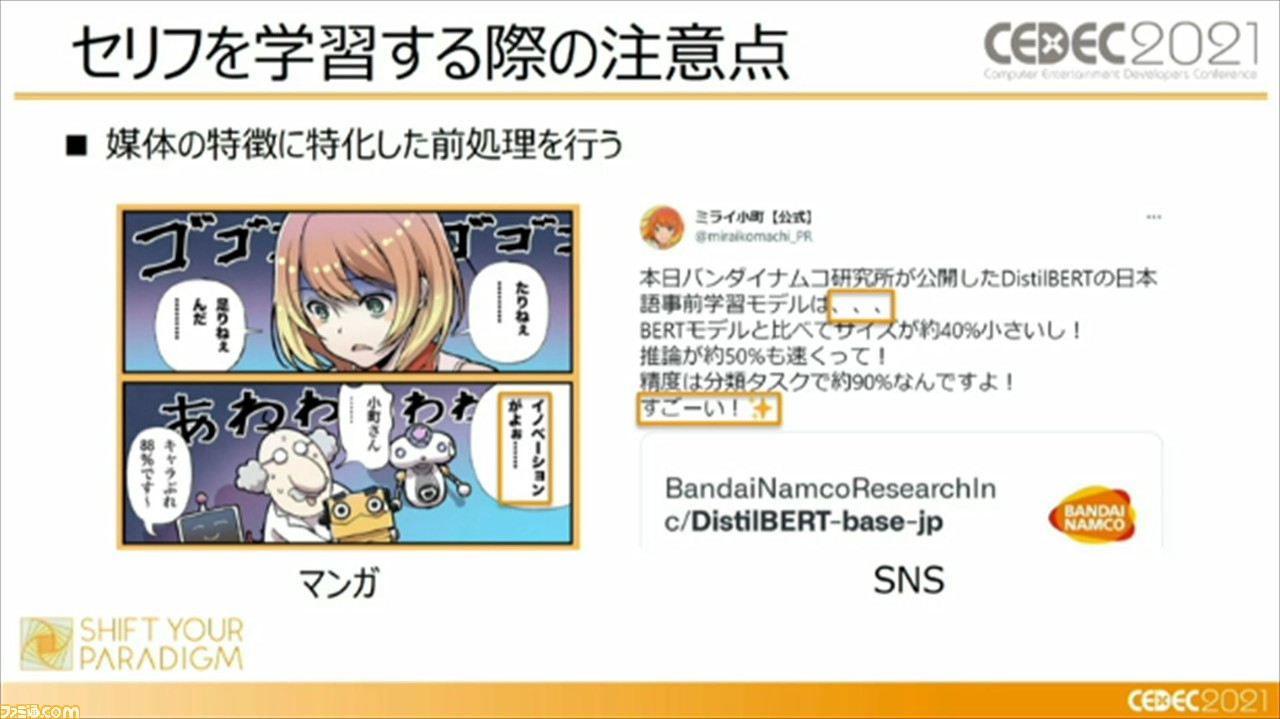
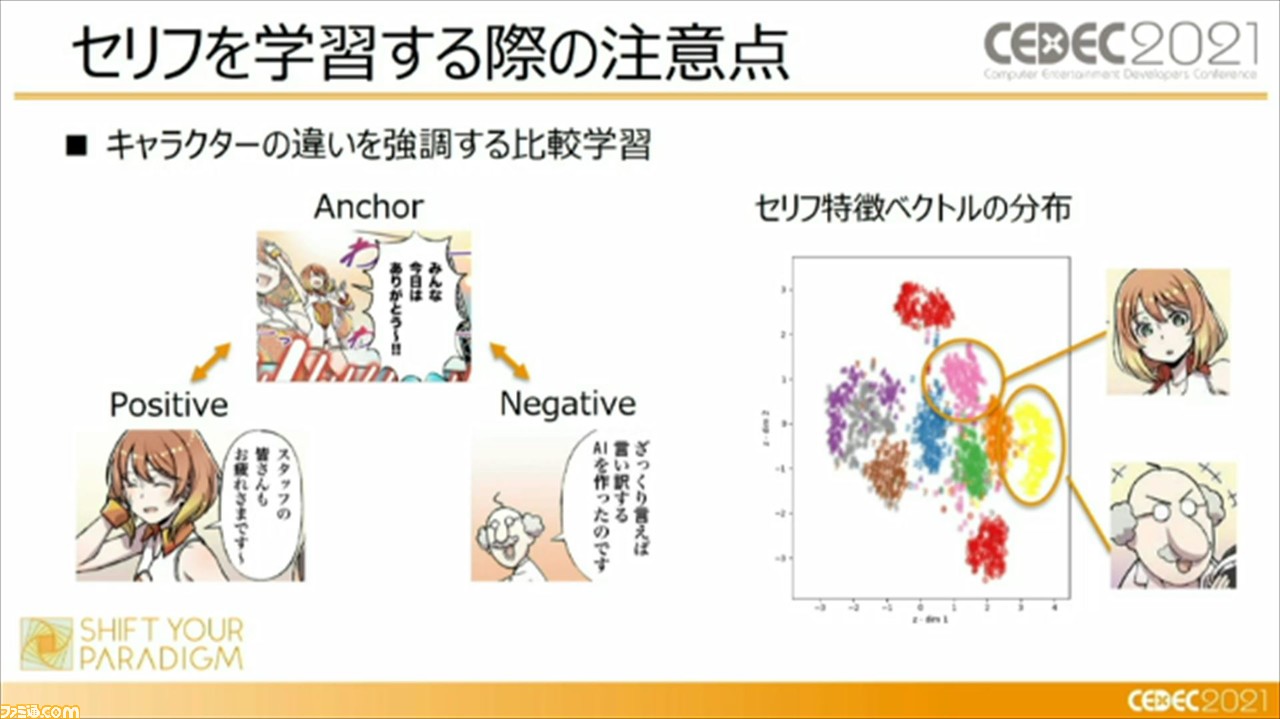
また、キャラクターの違いを強調する比較学習を用いることも重要とのこと。比較学習とは、セリフを学習するときに、セリフをひとつずつ学習するのではなくて、3つのセリフをひとつのグループとして学習する手法のこと。対象キャラクターのセリフ“アンカー”に対して、対象キャラクターによる別のセリフ“ポジティブ”、対象キャラクター以外の別キャラクターのセリフ“ネガティブ”にわけて学習したセリフの分布をバラけさせることで、対象キャラクターのセリフの特徴を、よりわかりやすくAIに学習させることができるそうだ。
これらを実際に行うために開発されたのが、セリフチェックツール“AIセリフ監督”。セリフ監修をキャラクターの個性・話しかたを学習したAIで支援するシステムであり、キャラぶれを発生させないために、シナリオライターがセリフ制作時に利用できるシステムとなっているとのこと。
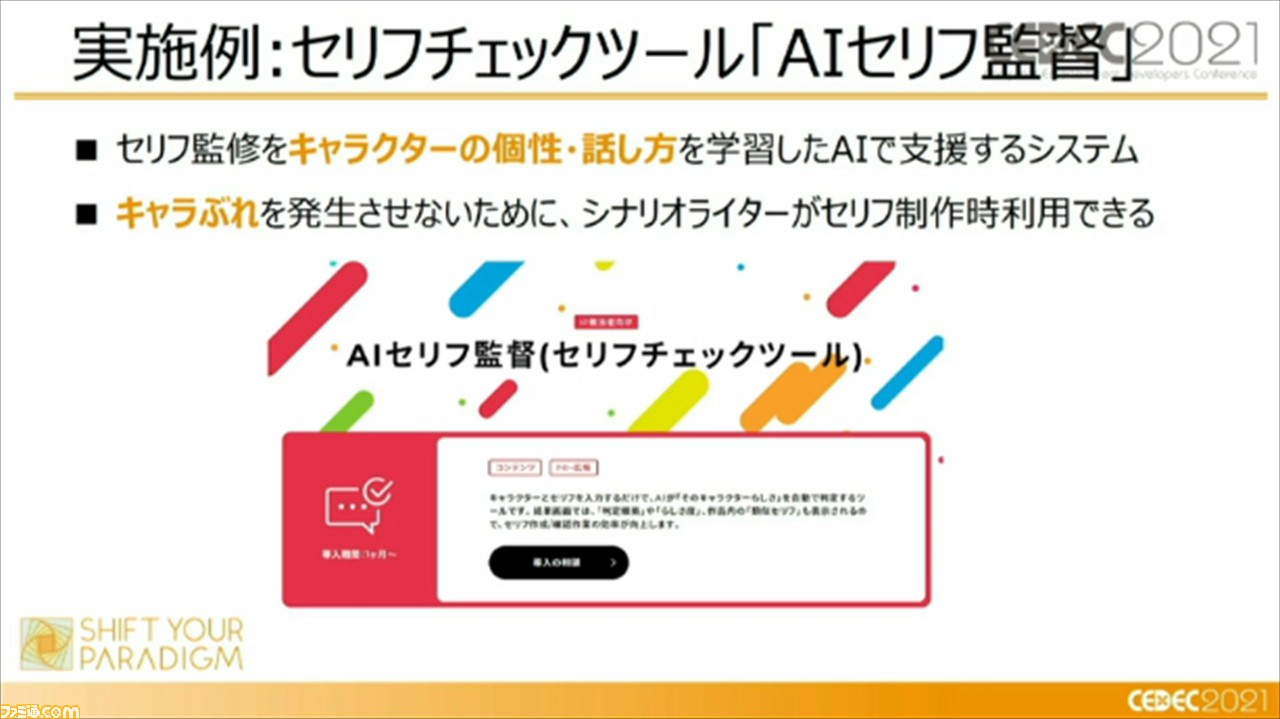
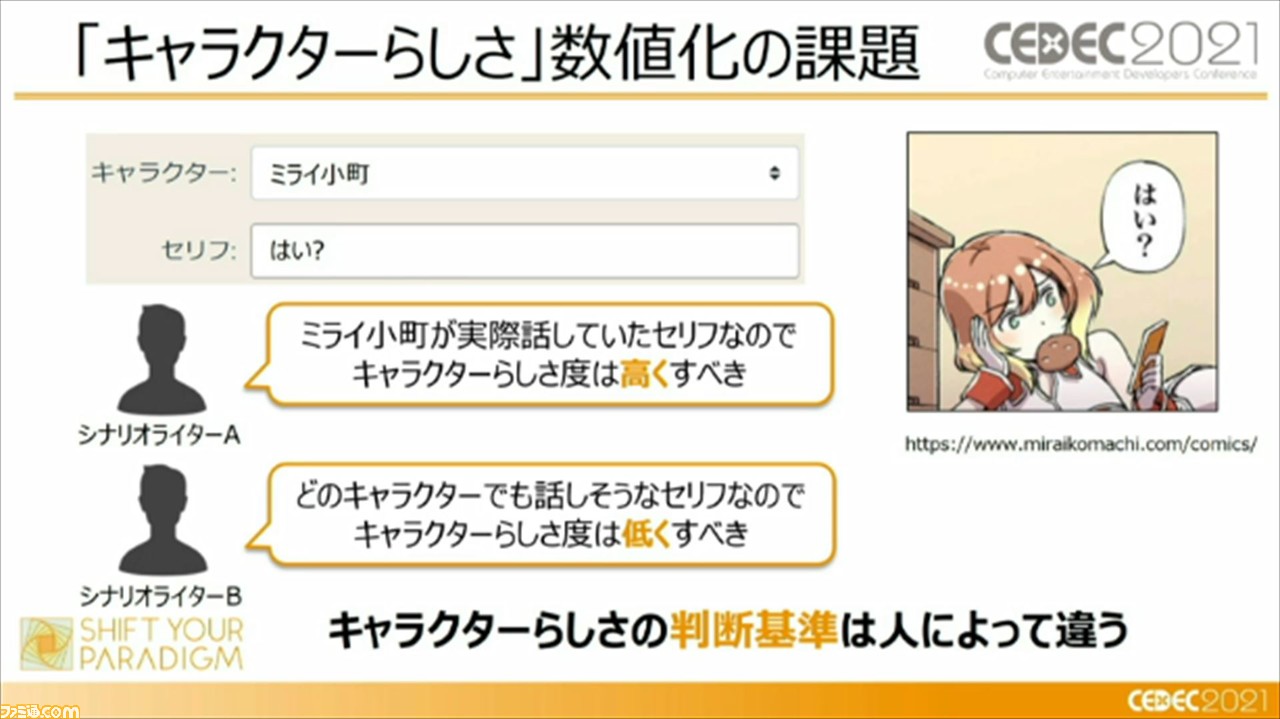
じつは、この“AIセリフ監督”と類似したシステムが、“CEDEC2016”の時点で登場していて、1セッション内で紹介もされたという。本ツールでは、入力したセリフのキャラクターらしさを数値かするというコンセプトを踏襲し、新たな手法、機能を追加して、シナリオライターがよりキャラクターらしさを抽出できるようにしているという。

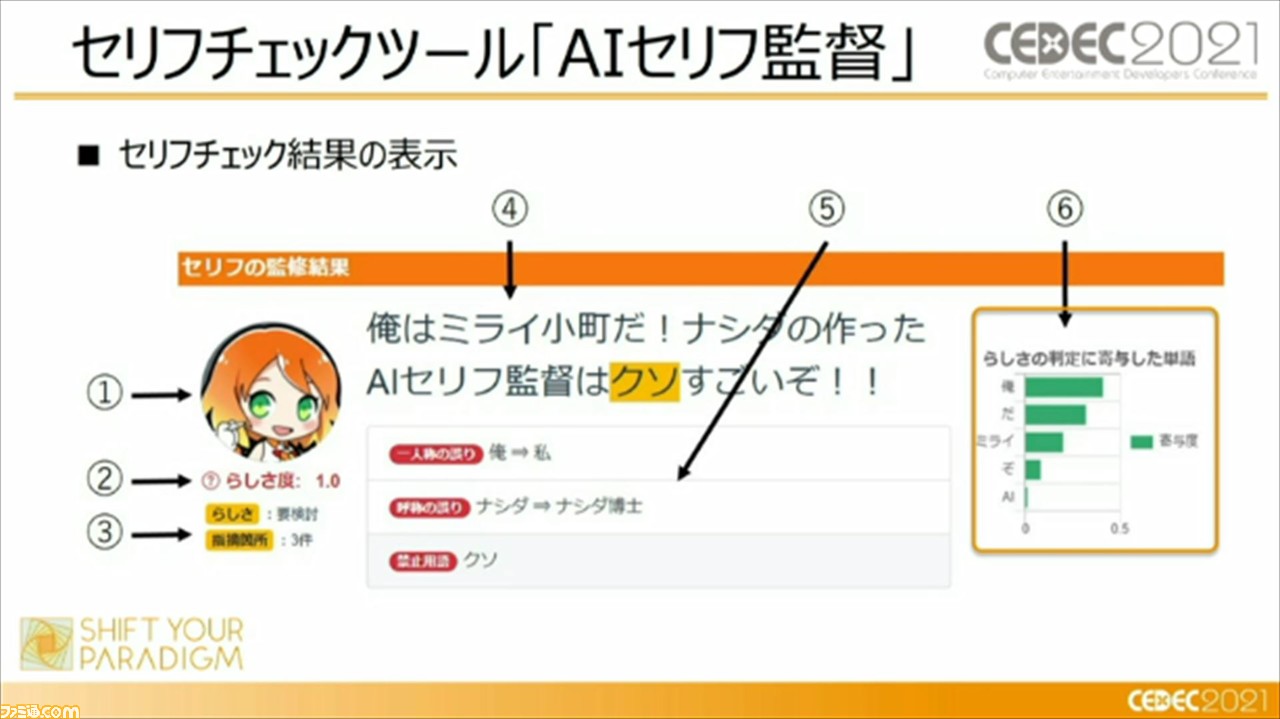
一方で、キャラクターらしさの数値化の課題として、キャラクターらしさの判断基準は人によって違う、という点を挙げる頼氏。この問題の解決策として、キャラクターの過去のセリフ履歴から類似の新規セリフを作成できる“類似セリフ検索”機能を実装したそう。この機能は、キャラクターらしさがシナリオライターによってぶれるのであれば、実績のある過去のセリフを参考にすればよい、という考えのもと追加されたそう。この機能では、言葉の意味で検索を行うため、類義語も対応でき、セリフの出典にも対応できるとのことだ。

こちらの機能を実装したことで、アニメ。マンガのゲーム化作品において、オリジナルのシナリオを実装する際の原作キャラクターのセリフ監修時に活用したり、類似セリフの抽出が役立っている、といったシナリオライターからのフィードバックについても触れ、現在、4社以上で導入され、複数のゲームタイトルの開発現場において活用されていると紹介した。

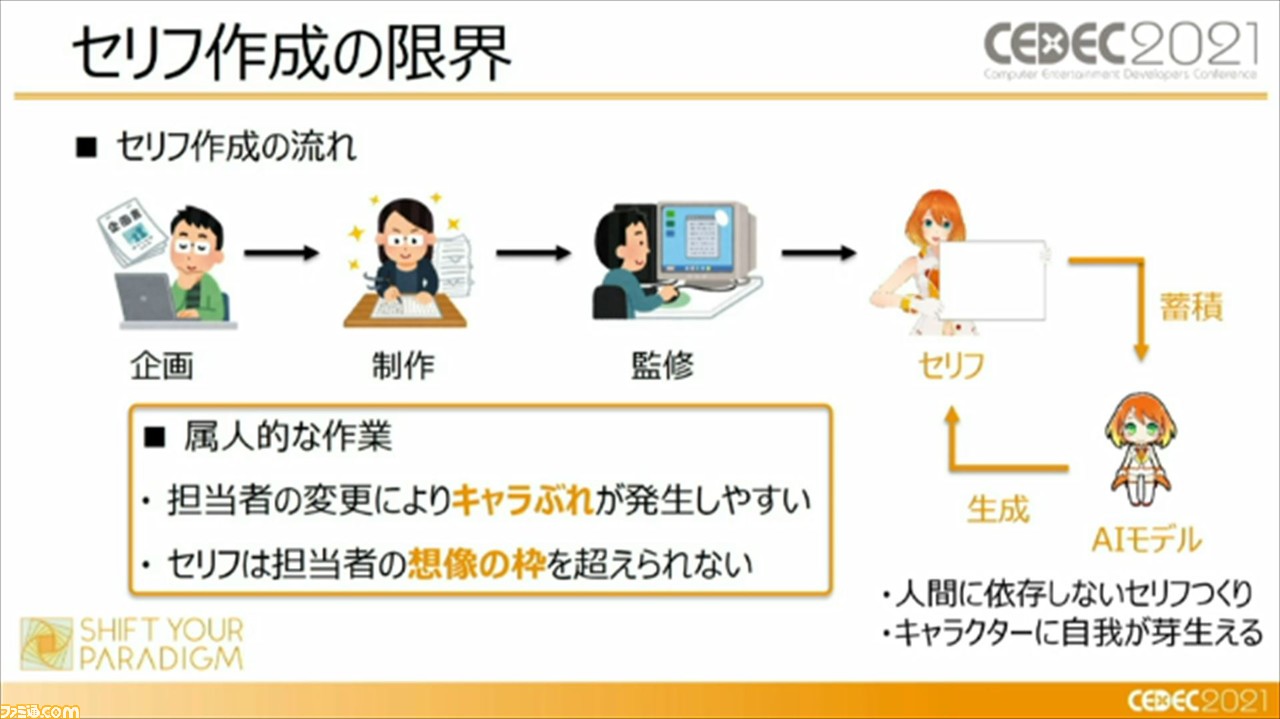
その一方で、セリフのみでユーザーに驚きや感動を与えるのは難しい、とも語る頼氏。それは、セリフ作成は属人的な作業ゆえ、担当者の変更によりキャラぶれが発生しやすい、セリフは担当者の想像の枠を超えられない、ということが理由であるという。この課題については、キャラクターの個性を学習したAIモデルによって新しいセリフを生成し、新しい個性データとして蓄積させることで対応。そうすることで、人間に依存しないセリフ作りができ、キャラクターの自我が芽生えることから、キャラクター性の反映にも繋がっていると説明した。
しかし、AIによるセリフの生成は簡単なことでないという。その理由は、自然なセリフを生成するためには、莫大なデータ量が必要であるからだ。Facebookが公開した、もっとも人間らしい会話ができるAI“BlenderBot”では、SNSの上の会話データ約15億件が必要だと言われいることからも容易に想像できると頼氏は語る。頼氏によれば、10年ほど連載したコミック作品に収録されているセリフの総数が10万件いくか、いかないかというボリュームであるそう。それゆえ、15億件のデータ量からAIを作るということは、非現実的であることがわかる。
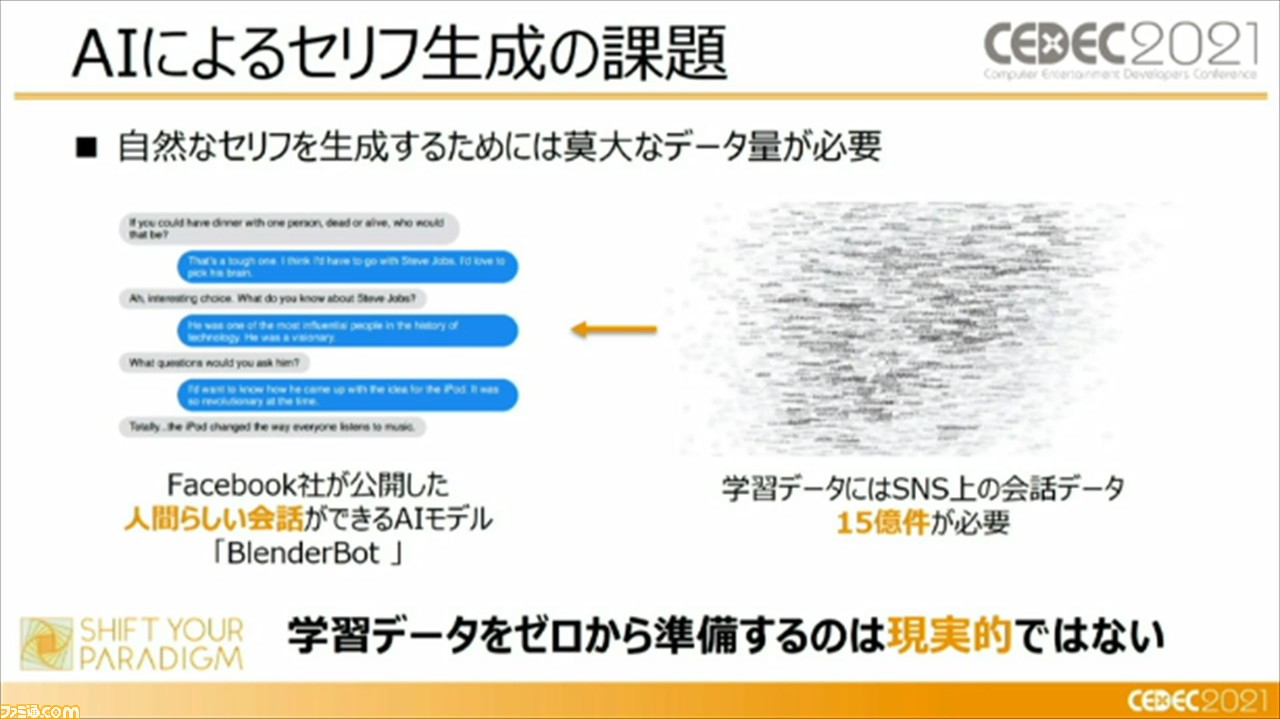
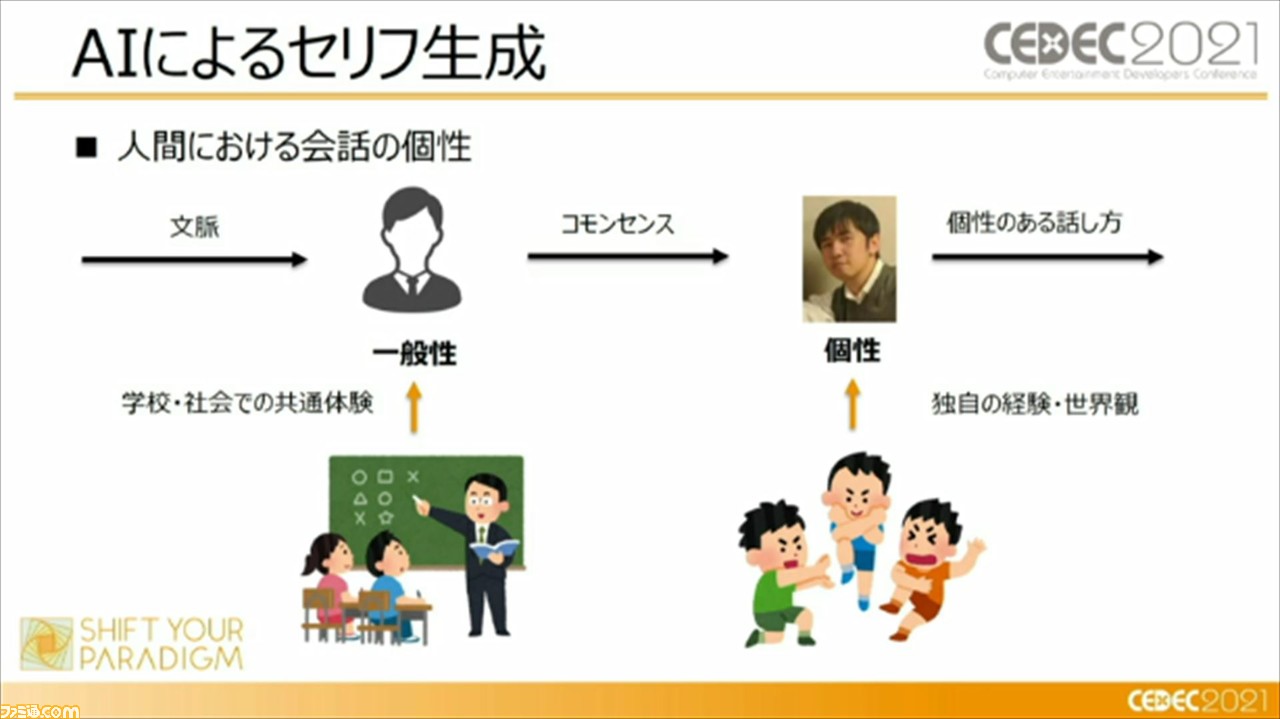
ここで頼氏から、人間の会話の個性はどのようにして生まれるか、ということが説明。我々人間でも、すべて自分の言葉で会話しているのではなく、まずは、学校や社会での共通体験をもって一般性を持つ。そこで一般性を持つからこそ、文脈に対して“コモンセンス(※)”を得ることができる。そして、1個人の経験や世界観を生かして、“コモンセンス”での会話を個性のある話しかたに変換することで、いまの会話が生まれているという。
※社会生活をする上で、誰もが知っているべき共通の認識。常識、良識とも言える。
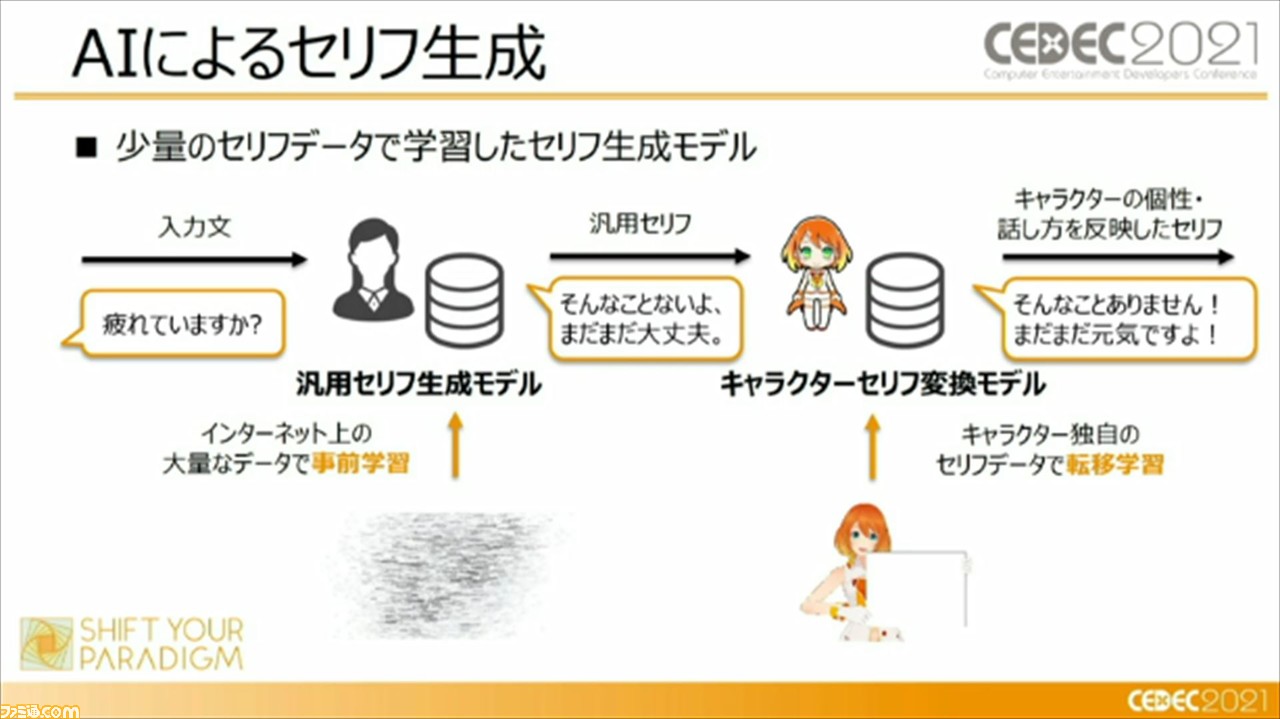
上記の過程を踏まえた上で、少量のセリフデータを学習したセリフ生成モデルを用意。インターネット上に存在している大量のデータで事前学習させて汎用セリフを生成し、そこから、キャラクター独自のセリフデータで転移学習させることで、キャラクターの個性や話しかたを反映したセリフを作成できることを可能にしたとのこと。
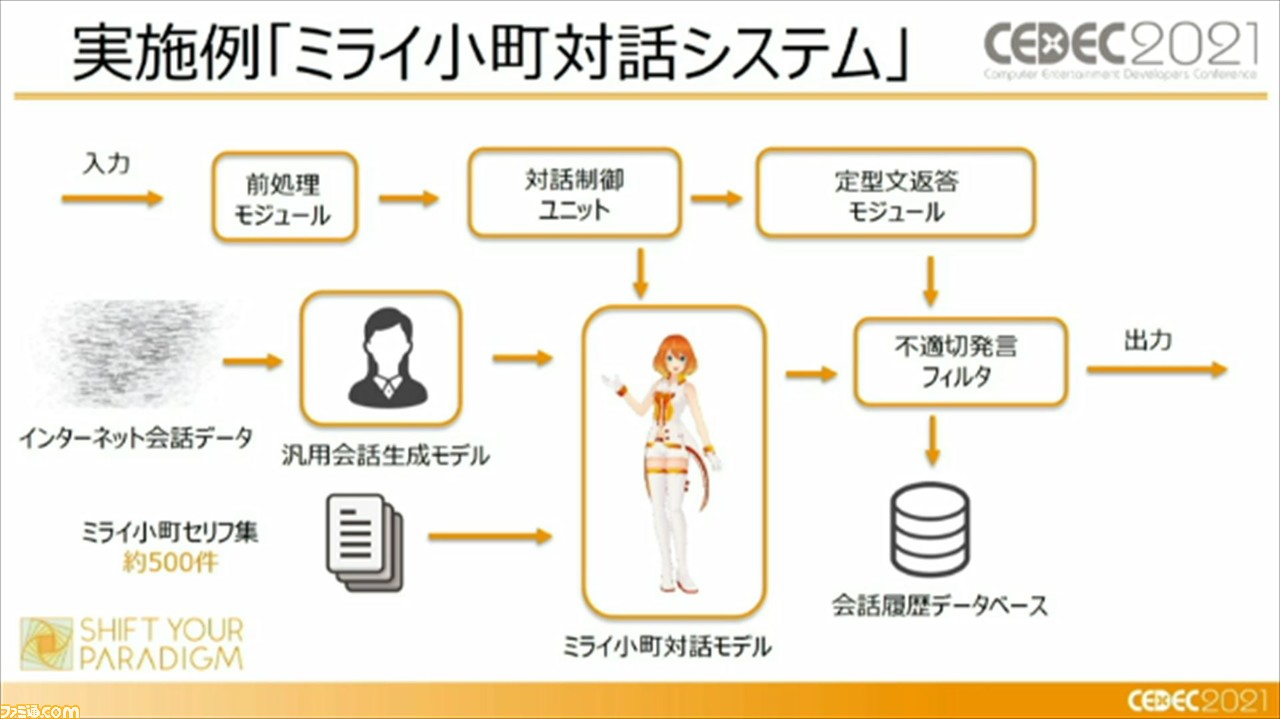
その実施例として、“ミライ小町対話システム”がある。このシステムでは、キャラクター独自のセリフデータであるミライ小町のセリフ集は約500件に収まっているとのこと。実際にバンダイナムコグループ内のチャットボットとして実装されており、世間話やグループIPに関する話題で雑談が可能であるそうだ。
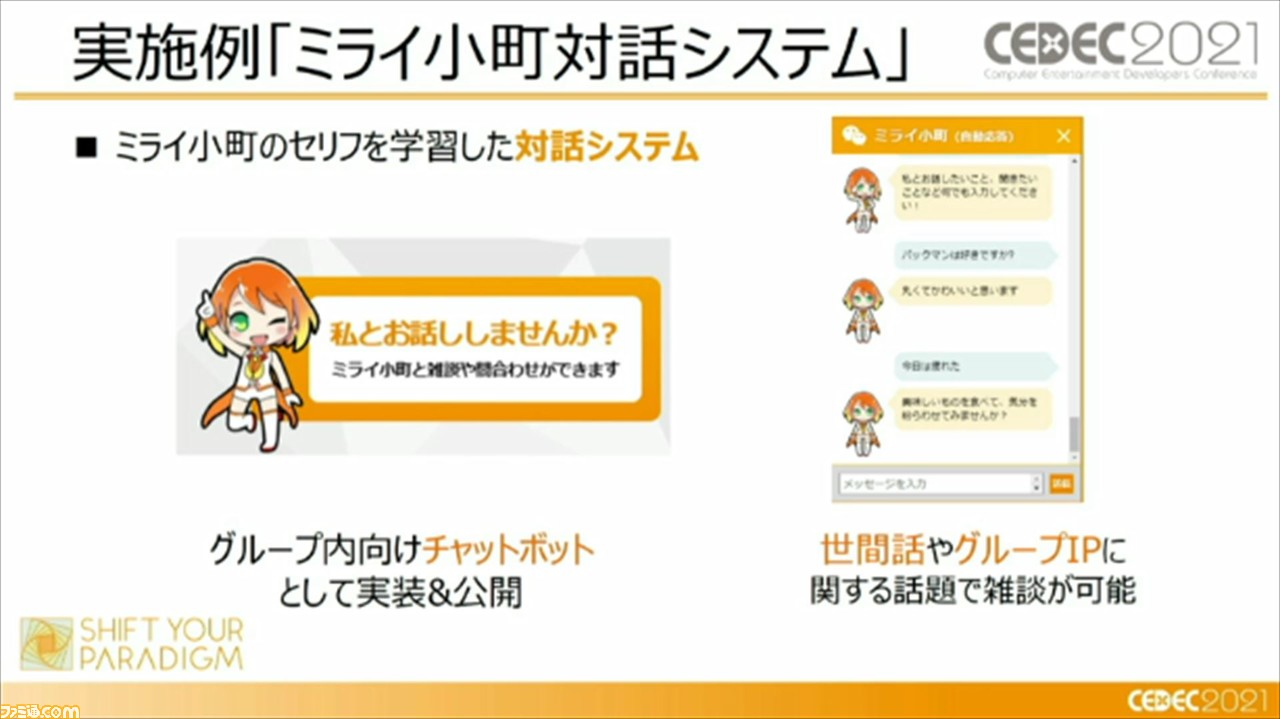
ここまでで、ディープラーニングを使用した、冴えるセリフの作りかたについての解説は終了。セッションの後半では、石原氏からルールベースを用いた手法が紹介された。

先ほど頼氏から説明があったように、ディープラーニングでキャラクターらしさを実現するためには、キャラクターのセリフデータが大量に必要であること、生成モデルがどう学習するかはブラックボックスであるため、品質の担保が困難であることが挙げられる。

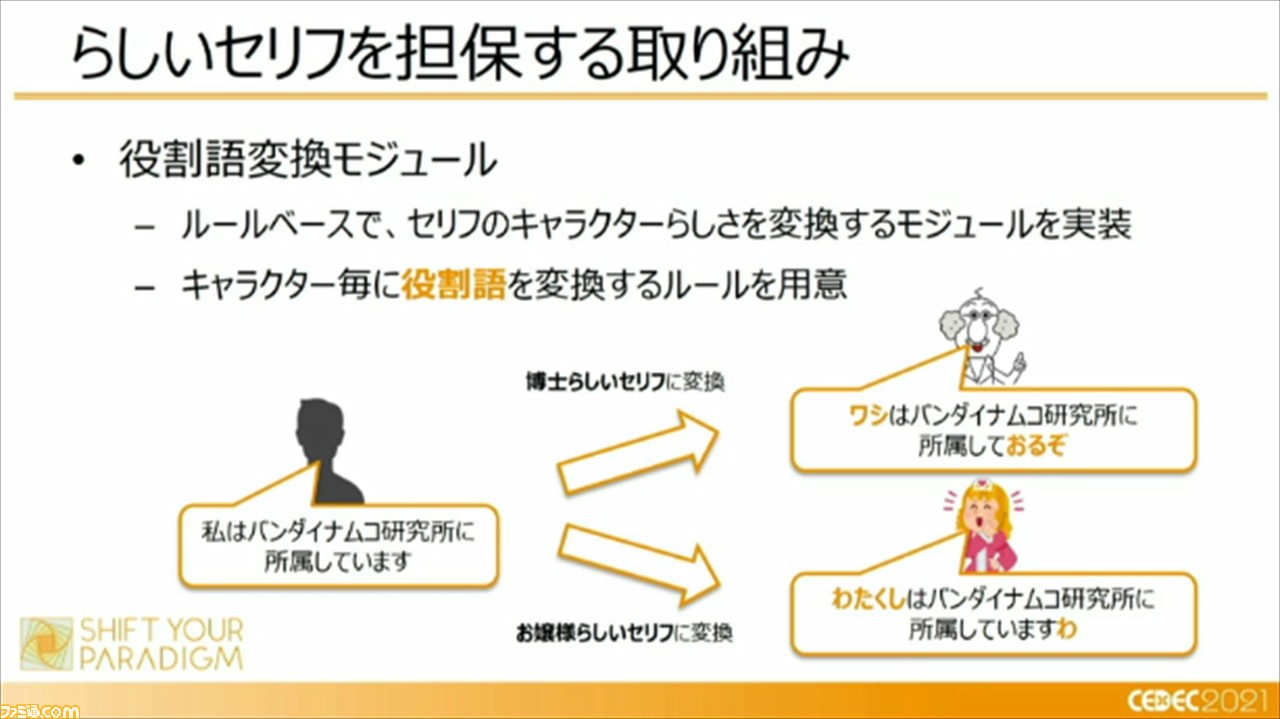
これらの課題に対して、らしいセリフを担保する取り組みとして“役割語変換モジュール”を実装し、活用しているという。これは、キャラクターごとに“役割語”を変換するルールを用意するというものだそう。
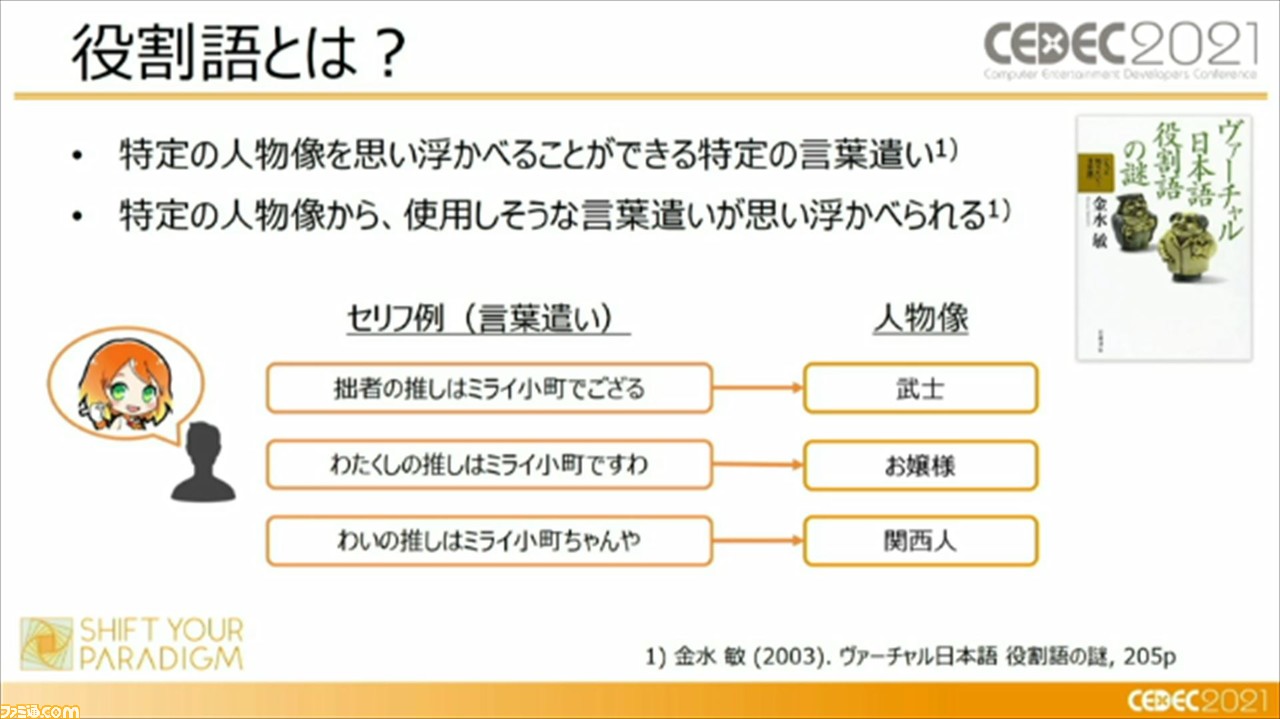
“役割語”は、日本語学者の金水敏氏が提唱したものだそうで、“特定の人物像を思い浮かべることができる特定の言葉遣い”もしくは、“特定の人物像から使用しそうな言葉遣いが思い浮かべられる”ものとして定義されているとのこと。セリフの語彙や語法が人物像を形成し、語彙や語法は、内容語や機能語にも違いとして現れるという。“役割変換モジュール”では、この機能語に着目して、キャラクターのセリフの変換におけるルール化を行っているそうだ。

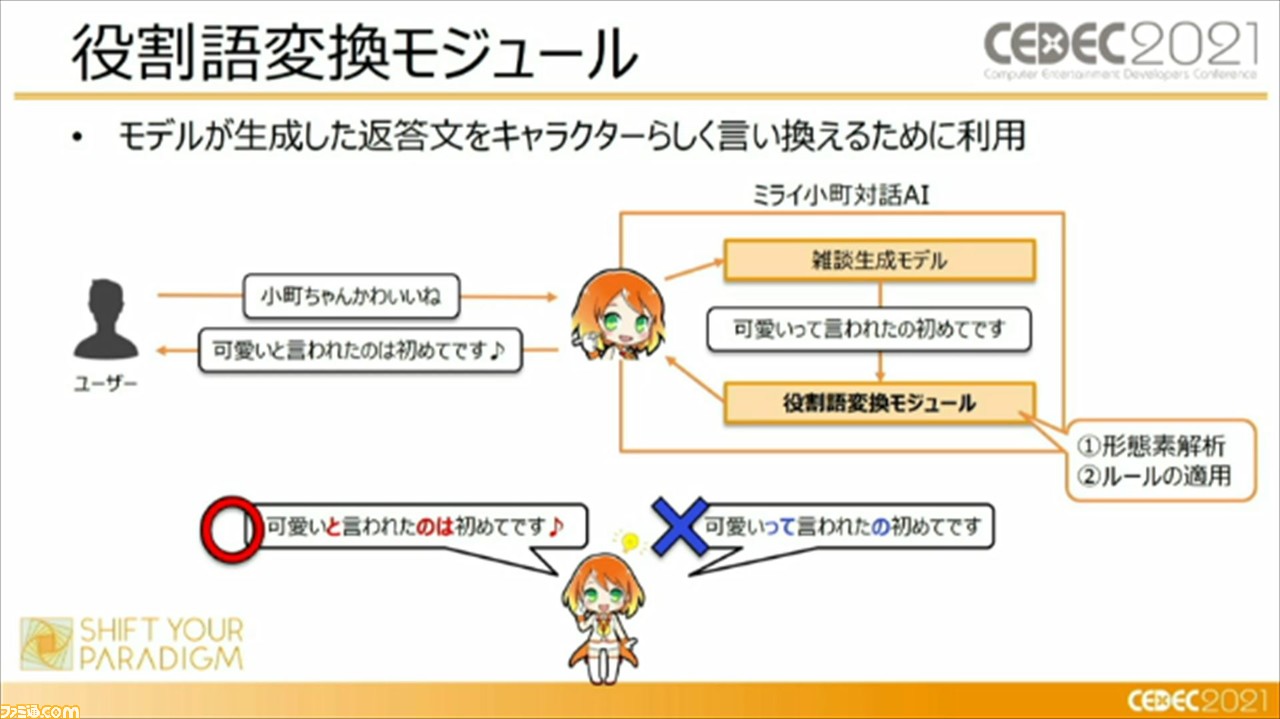
“役割変換モジュール”は、モデルが生成した返答文をキャラクターらしく言い換える、補正するために利用しているそう。具体的には、セリフを形態素という単語のような細かい単位に分割しつつ、品詞や活用形の情報を習得。それらを正規表現ベースの変換ルールに適用し、キャラクターらしい単語の並びに変換しているという。

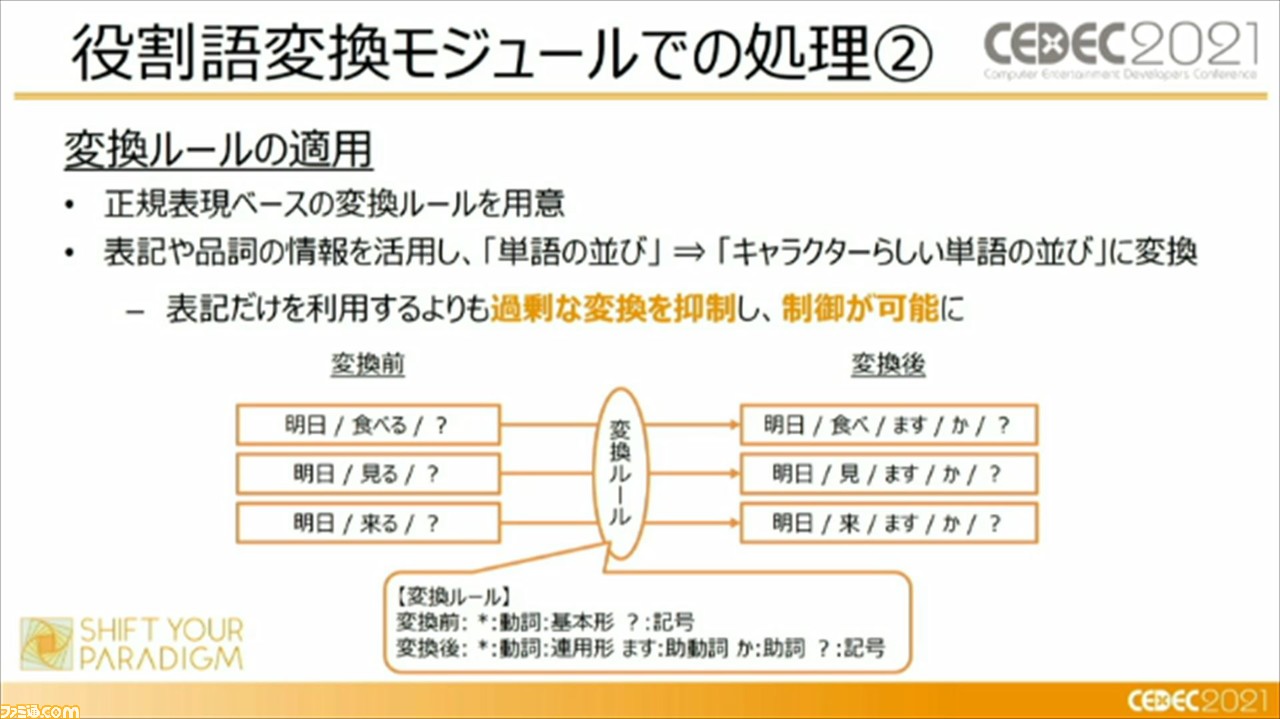
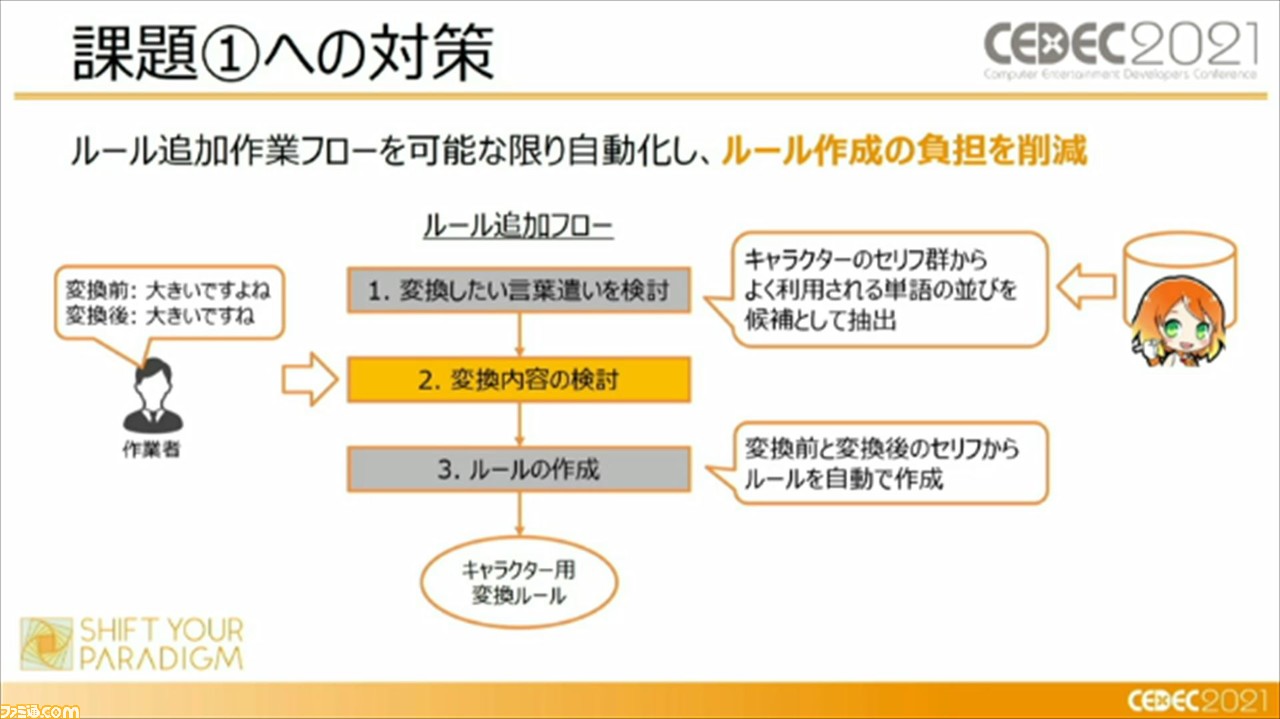
この“役割変換モジュール”にも課題はあるそう。ひとつは、変換ルールの作成コストが高いこと。これに対しては、ルール追加作業フローを可能な限り自動化し、ルール作成の負担を削減したそう。

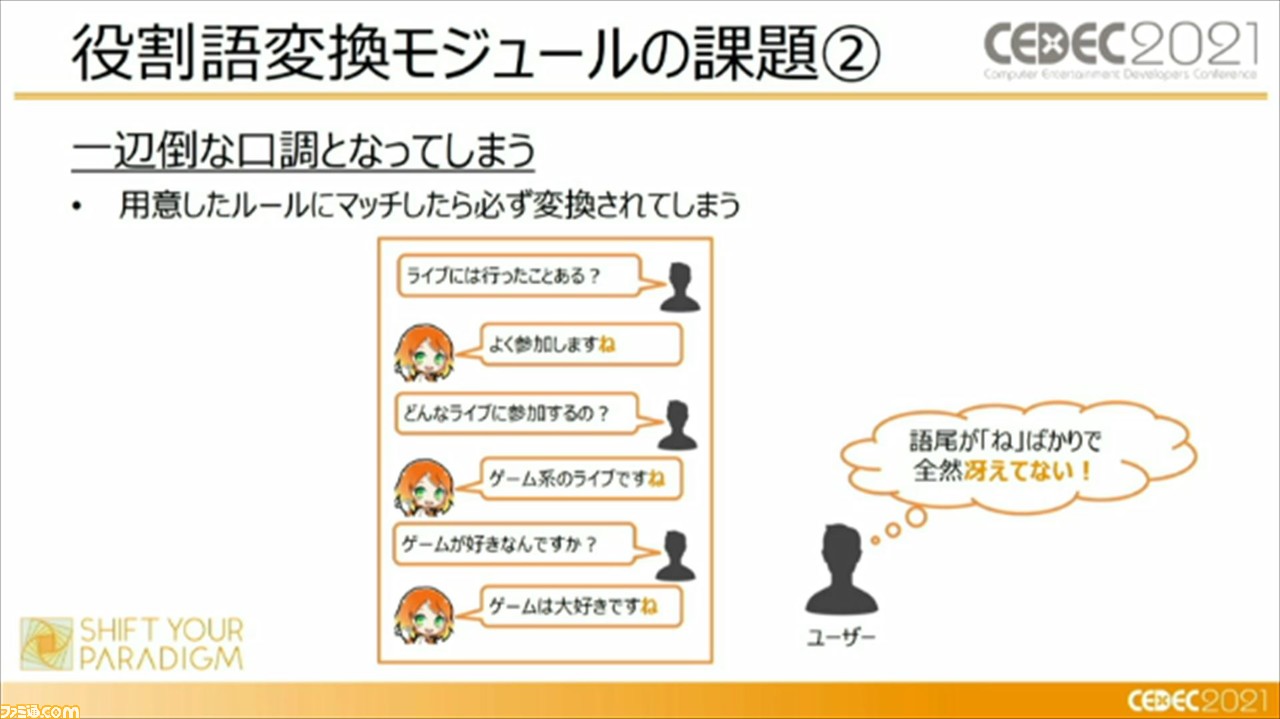
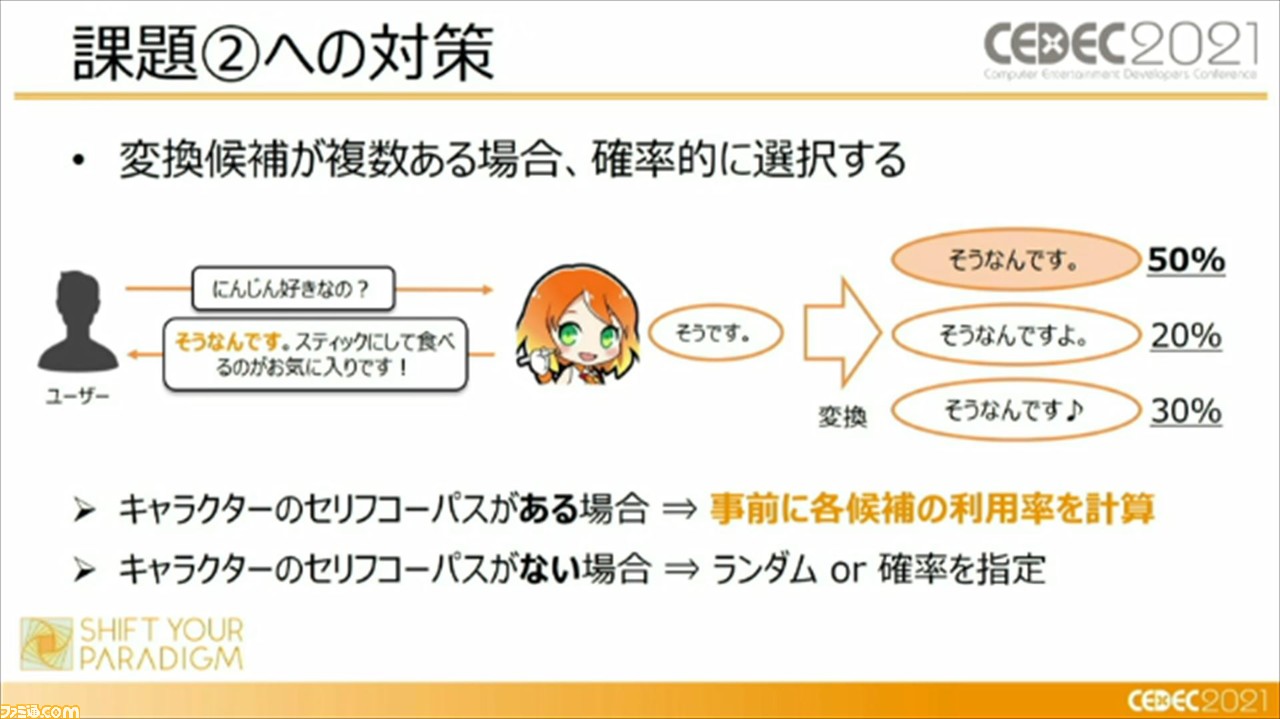
もうひとつは、一辺倒な口調になってしまうことだが、これには、変換候補が複数ある場合に確率的に選択する、ということで対策を行っているという。
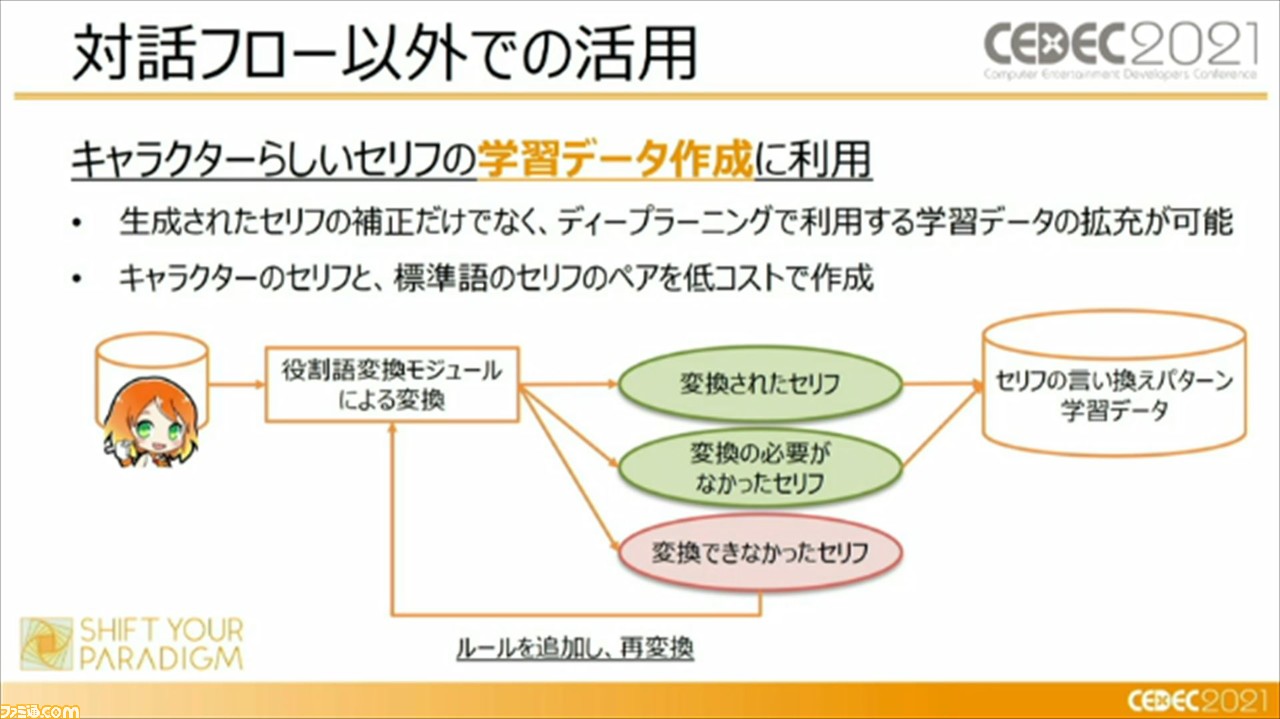
また、“役割変換モジュール”は対話フロー以外にも、キャラクターらしいセリフの学習データ作成にも利用されているそうだ。
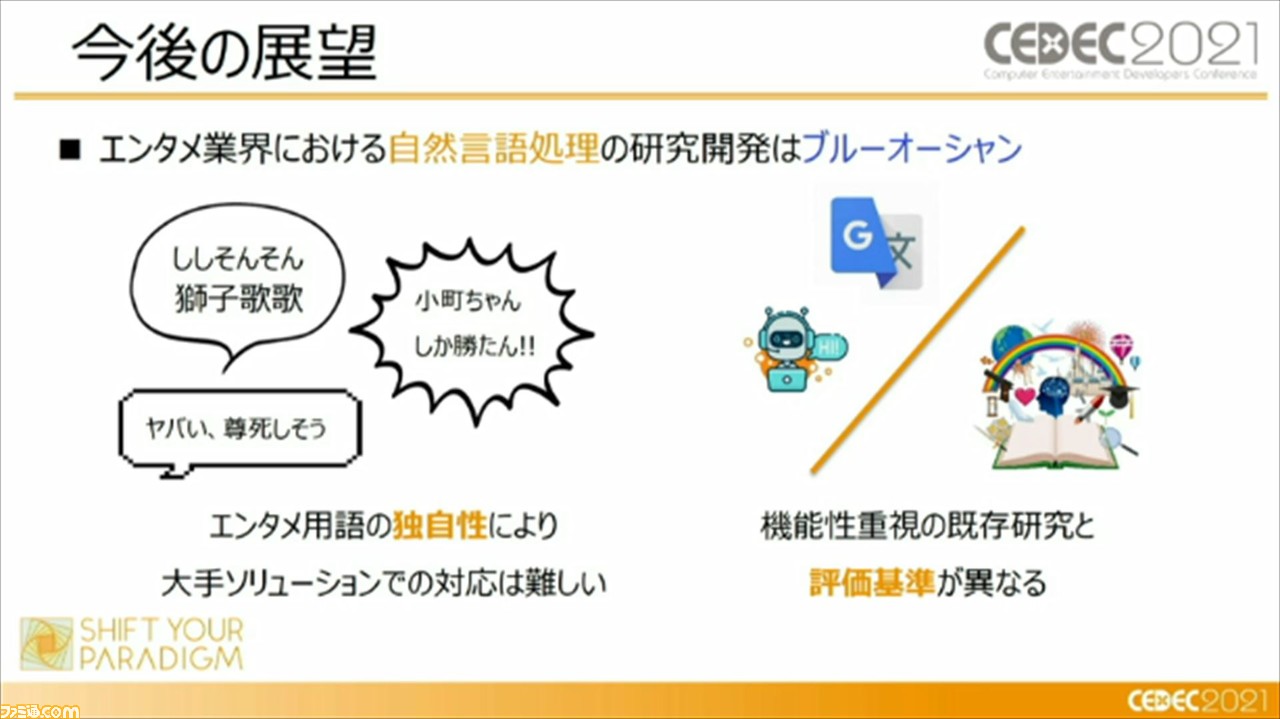
ルールベースを用いた実例が紹介されたところで、頼氏から本セッションの内容がまとめられつつ、今後の展望として、エンタメ業界における自然言語処理の研究はブルーオーシャンであることが言及された。これは、エンタメ用語の独自性により、Googleやマイクロソフトなど大手ソリューションでの対応が難しいことがあるという。たとえば、ネットスラングであったり、作品独自の表現が、他のソリューションを活用する際のハードルになっているのだそう。ほかにも、機能性重視の既存研究と評価基準が異なる点が挙げられるそうだ。

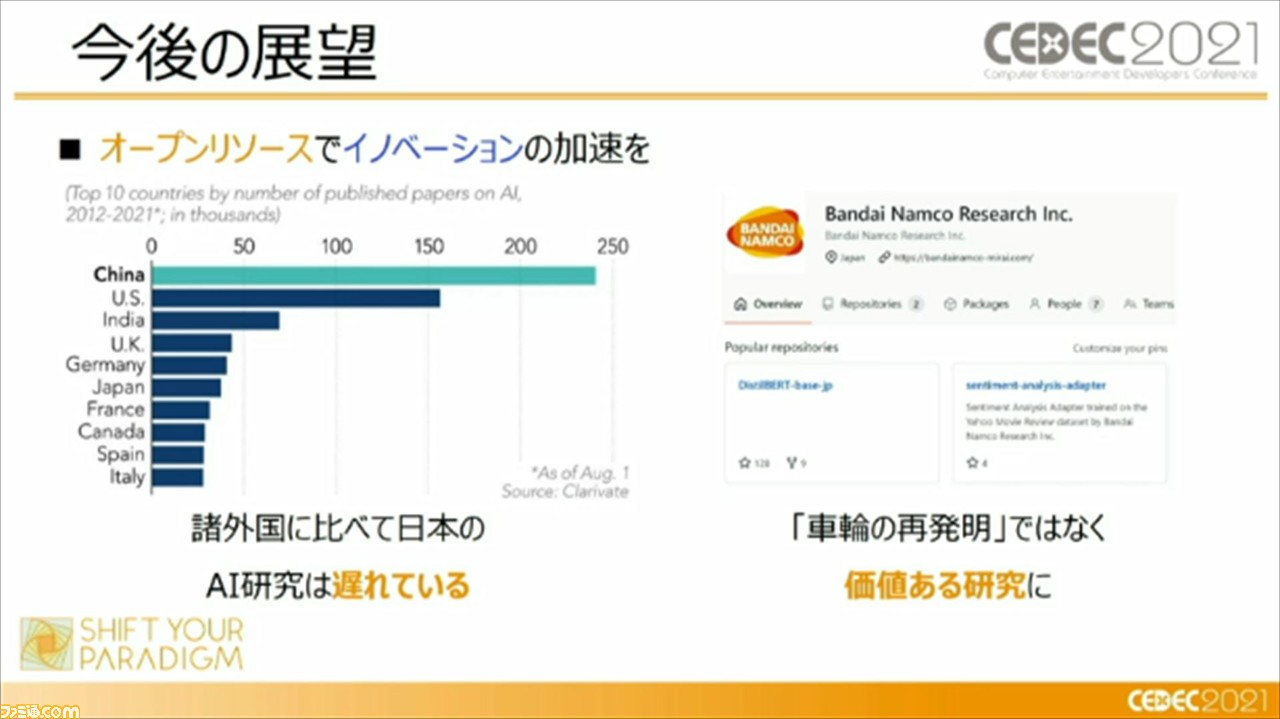
一方で頼氏は、諸外国に比べて日本のAI研究は遅れているとし、言葉の壁があるゆえ、日本独自の研究が必要と語る。これに対して、価値のある研究を収集するため、オープンソリソースでイノベーションの加速を行っていく必要があると、展望として語った。
そして最後に、より冴えるヒロインにしていくために、より豊かなセリフ表現と、セリフと連動したマルチマーダルモデル(※)について研究していくことが語られたところで、本セッションは終了となった。
※複数の種類の情報の入力データを利用したモデル。









