2022年8月23日から25日にかけての3日間にわたって開催された日本最大のコンピュータエンターテインメント開発者向けカンファレンス“CEDEC2022”。本稿では、最終日の8月25日に行われたセッション“AIによる自然言語処理を活用したゲームシナリオの誤字検出への取り組み”の内容をお届けする。
登壇したのは、サイゲームスで開発運営支援を行うゲームエンジニアの立福寛氏。立福氏は2019年後半からAIの社内導入に取り組んでおり、昨年のCEDEC2021では“ゲーム制作効率化のためのAIによる画像認識・自然言語処理への取り組み”という発表を行った。

立福氏による昨年のセッションはサイゲームスのYouTubeチャンネルで動画が公開されているほか、セッションで使用されたスライドや質疑応答の内容はサイゲームスのエンジニアブログにて公開されている。
今回のセッションでは、昨年紹介されたゲームシナリオ向けの誤字検出機能、そのバージョンアップにおける改善点や実装上の問題点、アプリケーションのUI改善やルールベースの誤字検出などについての解説が行われた。
AIによる自然言語処理に興味がある人がおもに楽しめる内容となっているが、UI改善の部分で触れられている内容は分野を問わずUIデザインや情報の見せかたを考えるうえで役に立つので、AIを扱わない人も要チェックだ。
従来の検出ツールと新バージョンの違い
まずは、昨年までの誤字検出ツールの開発状況に関する説明が行われた。サイゲームスでは社内向けのシナリオ執筆ツールを使用しており、そのユーザーからAIで誤字を検出してほしいとの依頼を受け、開発がスタートしたという。
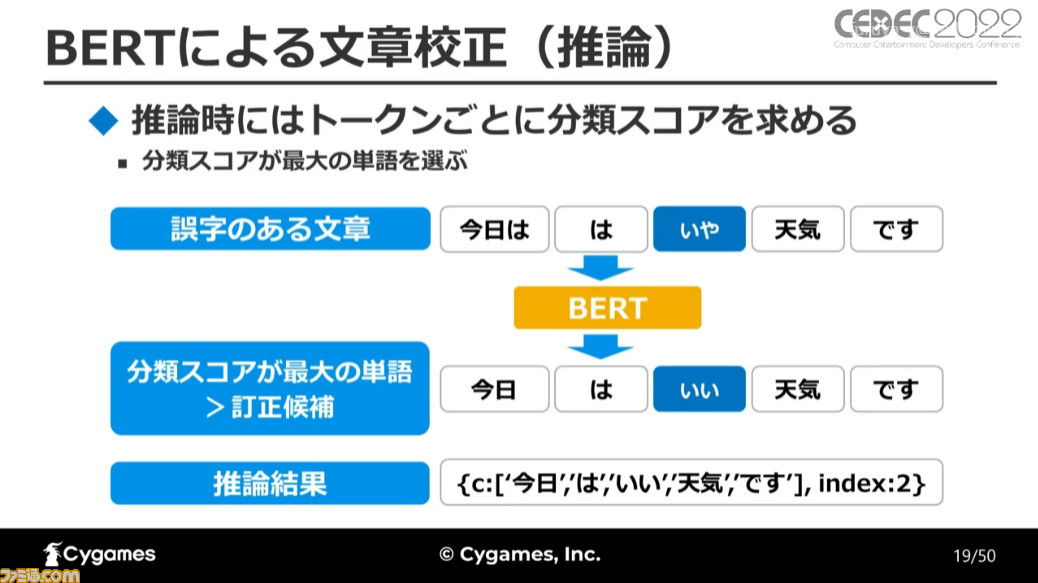
誤字には漢字の誤り、余計な文字の入り込み、補助動詞を漢字にしてしまう(“~してほしい”を“~して欲しい”にするなど)といった種類があり、まずは誤字の位置を求める機能が開発された。

誤字の位置は、3つのモデルから求められた。まずは文章を誤字あり、なしの2種に分類し、それらを形態素解析(文のなかで意味を最小単位=形態素に分解しての分析)にかけ、単語の出現順を求めることで誤字の位置を検出するのだ。

最初に作られた誤字検出機能は誤字の位置を判別できたものの、位置しか判別できないため誤検出だった場合の判断がつきにくく、また利用するユーザーが限られていたなどの課題が残されていた。
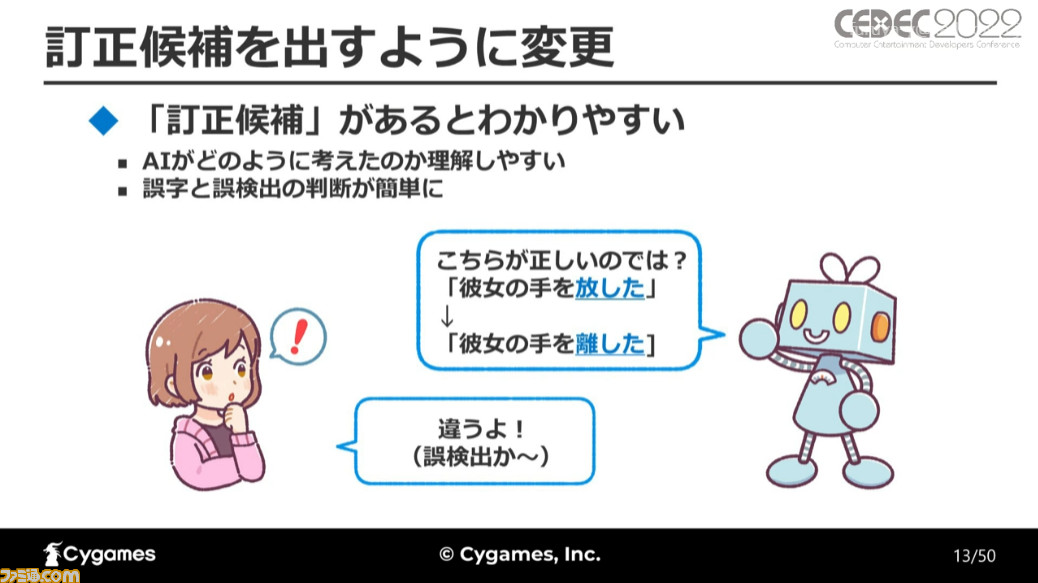
そこで、その後のバージョンでは誤字の位置に加えて訂正候補を提示するように変更。これによってAIがなぜ誤字だと判定したのかが理解しやすくなり、実際の誤字と誤検出とが区別しやすくなったという。

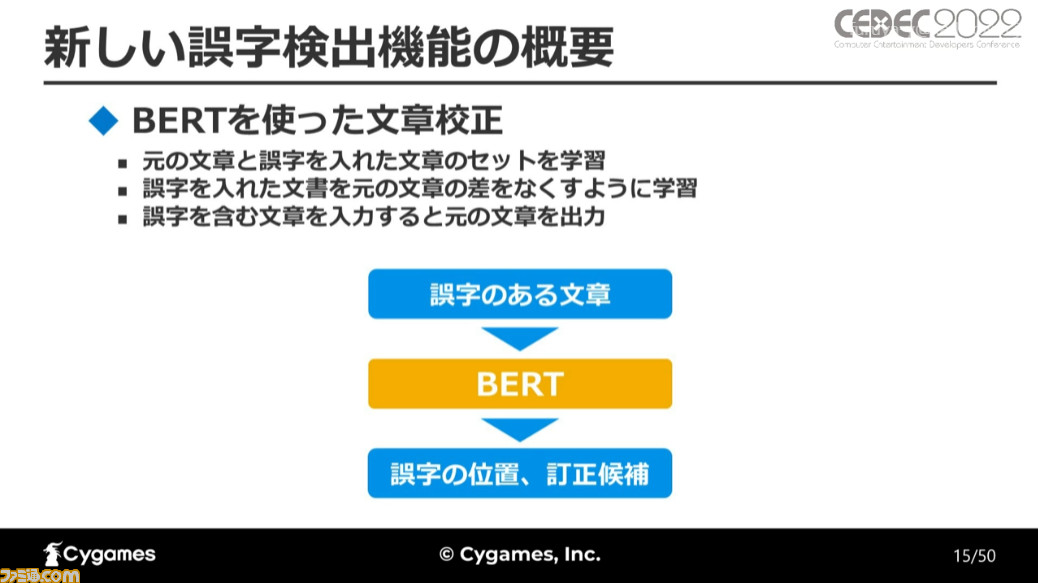
続いて、新しい誤字検出機能についての解説だ。誤字検出は2018年にグーグルから発表された自然言語処理モデルのBERTを使って行われた。前回の誤字検出機能でもBERTは使用しており、新しいモデルも登場しているが、慣れやドキュメントが充実しているという点から引き続き使用することになったという。

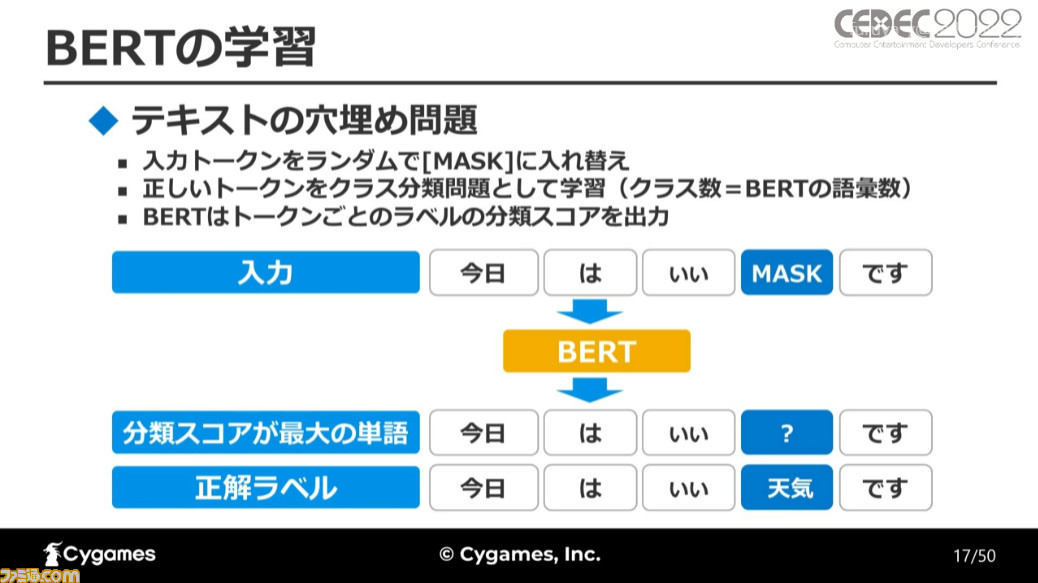
BERTの学習はテキストの穴埋め問題を通して行われた。入力トークン(形態素)をランダムにマスクデータと入れ換え、正しいトークンをクラス分類問題として学習させる。さらに誤字を含む文章を入力トークンとし、その正解として誤字のない文章を学習。
これにより、誤字のある文章を検出し、誤字を訂正した文章を出力できるようにしたのだ。

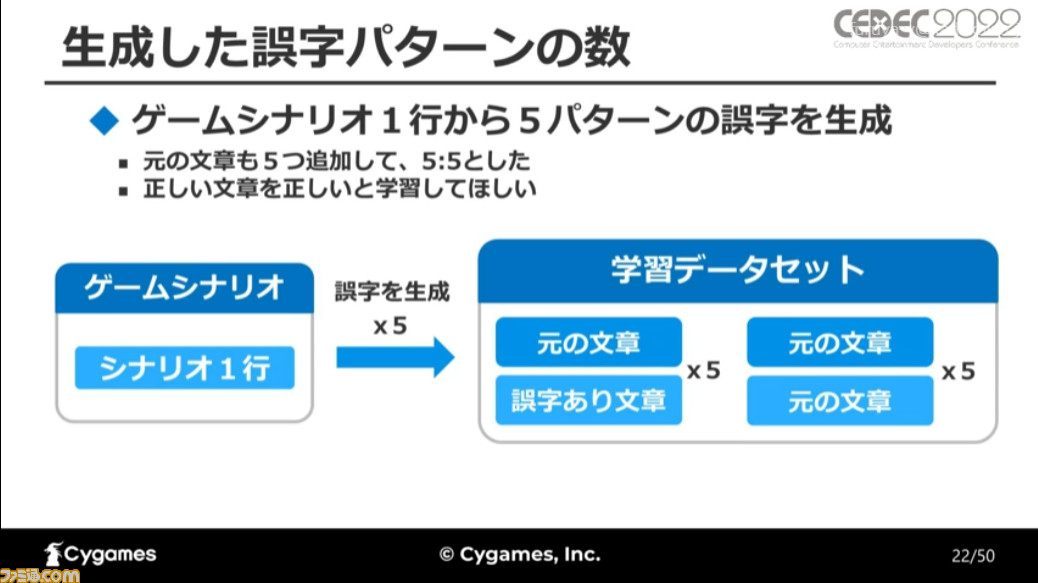
学習に使われたデータセットは、ゲームシナリオの文章と、それに独自の方法で誤字を入れ込んだ文章だ。ゲーム中に表示される1行の文をひとつのデータとし、元の文章からから5パターンの誤字を追加、さらに正しい文章が正しいと学習するために、元の文章も追加したという。
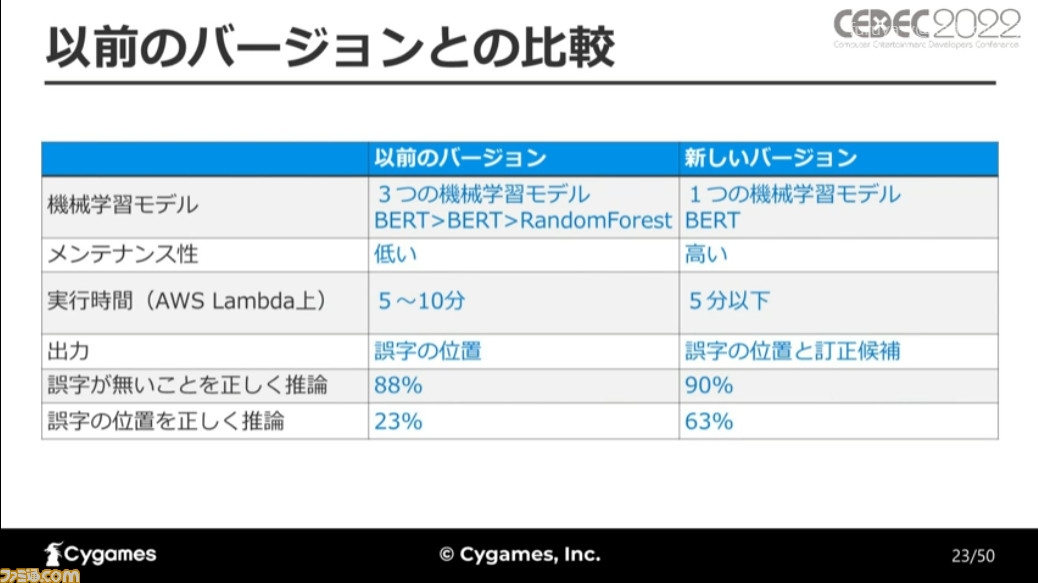
新バージョンは以前のバージョンと比べ、機械学習モデルをひとつしか使わないぶんメンテナンス性が高く、実行時間も短く仕上がった。誤字がないことを推論できる割合、誤字の位置を正しく推論できる割合も過去と比べて高くなっており、全体的に精度がアップしている。
誤字検出の学習とUIの改良
新たな誤字検出機能を実装するうえで、誤字パターンの改良とトークンのマッチングにおける工夫がなされた。
以前のバージョンでは、7つの誤字パターンを含む単語リストを使って誤字の入れ換えを行っていたが、新たなバージョンでは“日本語ウィキペディア入力誤りデータセット”を導入し、データ量が大幅に増加。
日本語ウィキペディア入力誤りデータセットは入力の誤りを訂正する前後の文章や訂正された単語などがまとまったデータになっており、誤字検出機能ではそのうちの訂正が行われた単語を使用。
訂正後の単語をシナリオから検索し、その単語を訂正前の誤字に置き換えたものを学習させ、検知できる誤字の範囲路広げたという。


誤字検出機能はトークンの数が一致していないと処理が行えず、誤字のある文章と元の文章とで形態素の数が異なると処理が行えなかった。そこで、ふたつの文章のトークン数がずれている場合、元の文章にPADを挿入することで数を調整し、最終的な推論の出力時にはPADを削除することで解決したという。
これらの変更により、最終的には誤字のない文章の約90%、誤字のある文章を約70%の精度で検知でき、誤字の位置については60%程度、誤字の訂正については30%強の精度で検出・訂正が行えるようになったとのことだ。


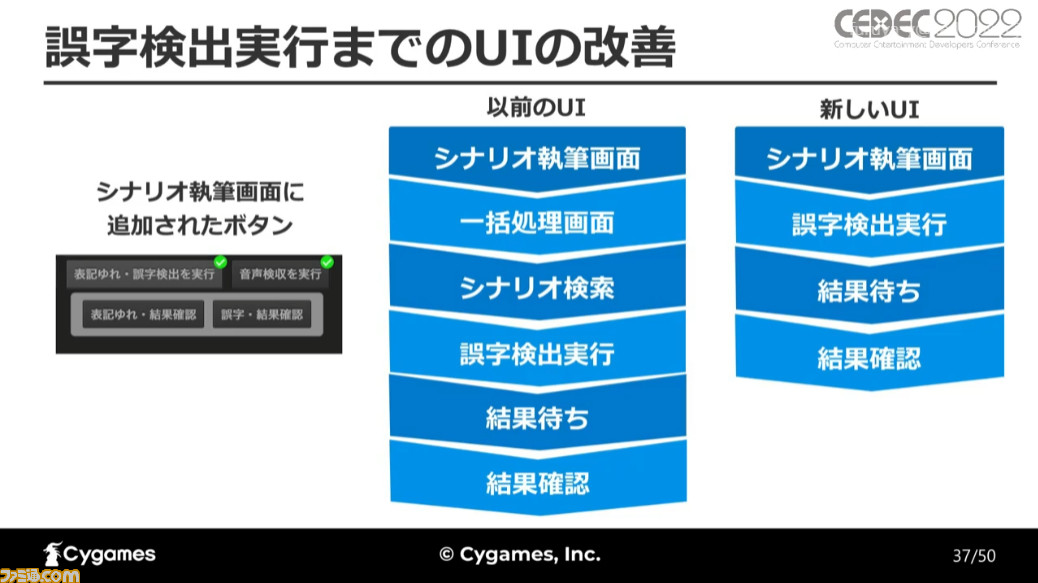
以前から導入されていた誤字検出機能だが、前述の通り利用するユーザーは限られていた。その原因を調べると、誤字検出を行うボタンが執筆中に使う画面とは別の画面に配置されていたことが問題だったという。
別画面への実装はUI面での工数は少ないものの、画面遷移を挟んでしまうために使い勝手が悪いものになっていた。AIを開発しても、UIが悪いと使われない、というのが立福氏の直面した問題だ。


そこで、シナリオ執筆に使用するメイン画面のUIを改良し、検出機能の実行ボタンを同じ画面内に追加。これにより、以前のUIと比べて検出を行い、その結果を確認するまでの手間が減り、手軽にチェックが行えるようになったという。
AIを利用したルールベースの文章校正機能
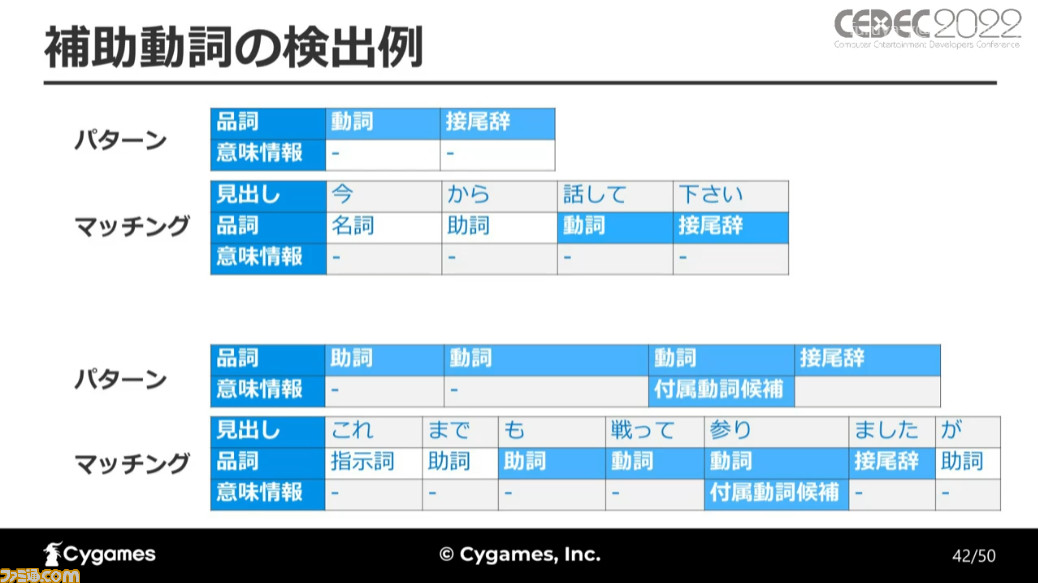
最後に紹介されたのが、ルールベースの文章校正機能だ。ルールベースのものにはむずかしい漢字の検出、補助動詞の漢字を検出、そして“ら抜き言葉”を検出するものがある。むずかしい漢字についてはシンプルに対象となる漢字のテーブルを持たせ、マッチングするだけだ。

補助動詞が漢字になっている部分の検出は、日本語の形態素解析システム“Juman++”を利用し、検出したい文章から品詞の並びと意味情報をパターン化し、そのパターンを登録して行われた。品詞と意味情報のパターンを20件ほど作成することで、ある程度の検出ができるようになったとのことだ。

ら抜き言葉については、Web記事を参考に判定方法を構築していったという。こちらもJuman++を利用し、形態素の代表表記と活用形を使用。トークンの代表表記が“れる/れる”であり、ひとつ前にあるトークンの活用形が未然形、カ変動詞来、母音動詞であったものを検出対象とした。
ら抜き言葉の検出をシナリオ全体でテストしたところ、検出数158件に対し、正解148、誤検出10とかなりの精度で検出ができたという。見逃しているケースがないわけではないが、誤検出が少ないのは数字を見れば一目瞭然だ。



最後のまとめとして、立福氏は講演の内容を振り返った。今回はBERTを使った誤字検出機能の開発、検出に使用した学習データセットの作成、機能を利用してもらうためのUI改良、そしてルールベースの文章校正に関する解説が行われた。
とくにテキスト量が多くなるアドベンチャーゲーム、RPGなどの作品では、AIを使った自然言語処理が活用できれば開発はかなりスマートに進められるだろう。セッションの最後には参考文献も紹介されたので、興味がある人はそちらも要チェックだ。










